Hashing optimizes data retrieval by transforming keys into fixed-size hash codes that directly map to storage locations, ensuring constant-time access on average. Indexing improves search efficiency by creating auxiliary data structures that maintain sorted representations of the records, enabling faster query performance, especially for range searches. Explore our detailed comparison to understand which technique best suits your database needs.
Main Difference
Hashing stores data by converting keys into fixed-size hash codes, enabling constant-time average retrieval, ideal for exact-match queries. Indexing organizes data through structures like B-trees or bitmap indexes, supporting efficient range queries and sorted data access. Hashing offers quick, direct access without order preservation, while indexing maintains data order to facilitate range searches and partial key matches. Both optimize data retrieval but serve distinct use cases based on query types and data organization needs.
Connection
Hashing and indexing are connected through their role in optimizing data retrieval processes in databases. Hashing uses a hash function to map data to specific locations, enabling constant-time access, while indexing creates a data structure that improves search efficiency by organizing keys and pointers. Combining hashing with indexing enhances query performance by reducing search space and accelerating data lookup operations.
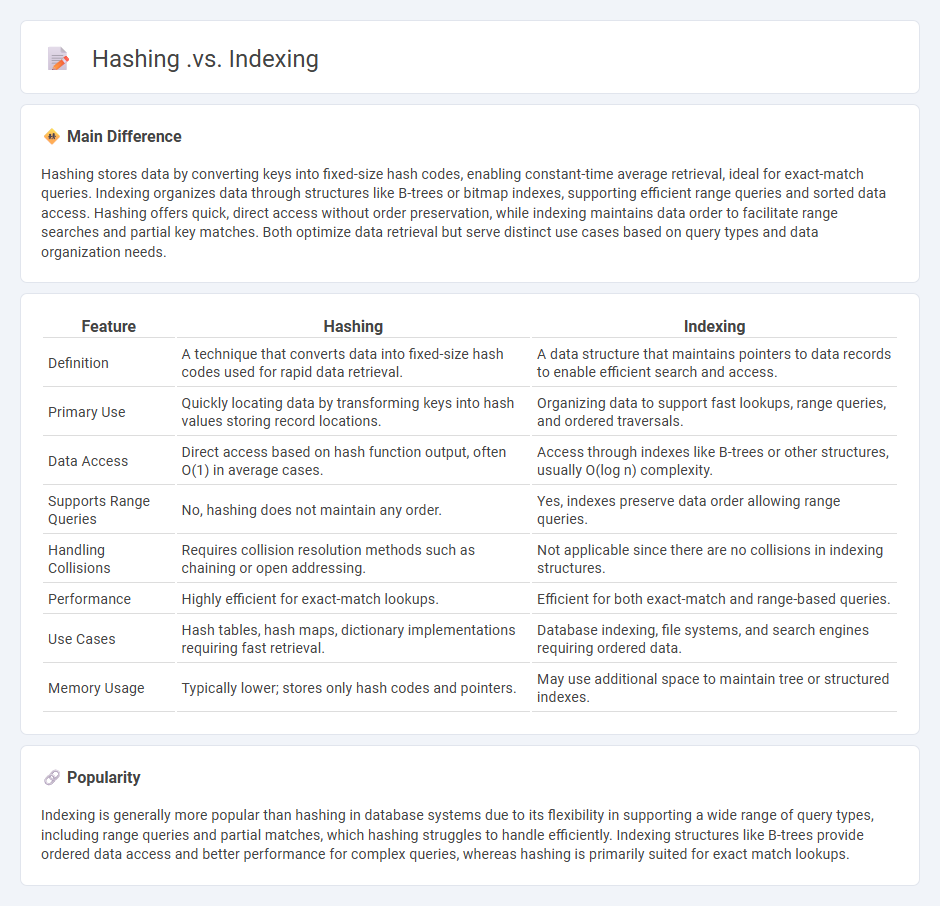
Comparison Table
| Feature | Hashing | Indexing |
|---|---|---|
| Definition | A technique that converts data into fixed-size hash codes used for rapid data retrieval. | A data structure that maintains pointers to data records to enable efficient search and access. |
| Primary Use | Quickly locating data by transforming keys into hash values storing record locations. | Organizing data to support fast lookups, range queries, and ordered traversals. |
| Data Access | Direct access based on hash function output, often O(1) in average cases. | Access through indexes like B-trees or other structures, usually O(log n) complexity. |
| Supports Range Queries | No, hashing does not maintain any order. | Yes, indexes preserve data order allowing range queries. |
| Handling Collisions | Requires collision resolution methods such as chaining or open addressing. | Not applicable since there are no collisions in indexing structures. |
| Performance | Highly efficient for exact-match lookups. | Efficient for both exact-match and range-based queries. |
| Use Cases | Hash tables, hash maps, dictionary implementations requiring fast retrieval. | Database indexing, file systems, and search engines requiring ordered data. |
| Memory Usage | Typically lower; stores only hash codes and pointers. | May use additional space to maintain tree or structured indexes. |
Hash Function
A hash function in computer science is a specialized algorithm that transforms input data of arbitrary size into a fixed-size string of characters, typically a sequence of numbers or letters. It plays a crucial role in data structures like hash tables, enabling fast data retrieval through unique hash codes. Cryptographic hash functions such as SHA-256 ensure data integrity and are fundamental in security protocols by producing irreversible and collision-resistant hashes. Efficient hashing improves the performance of databases, caching systems, and digital signatures across computing applications.
Search Key
A computer is an electronic device designed to process data by executing programmed instructions. Modern computers utilize central processing units (CPUs) with multiple cores, high-speed RAM, and solid-state drives (SSDs) to enhance performance and multitasking capabilities. Operating systems such as Windows, macOS, and Linux manage hardware resources and provide user interfaces for software applications. Advanced computers support complex tasks including artificial intelligence, data analysis, and real-time graphics rendering.
Index Structure
Index structure in computer systems organizes data to enable efficient retrieval and storage operations. Common types include B-trees, hash indexes, and bitmap indexes, each optimized for specific query patterns and data types. B-trees maintain sorted data and support range queries with O(log n) complexity, widely used in database management systems like MySQL and PostgreSQL. Hash indexes provide constant-time access for equality searches, while bitmap indexes efficiently handle low-cardinality attributes in data warehousing environments.
Collision Resolution
Collision resolution in computer science refers to techniques used to handle conflicts that occur when multiple data inputs compete for the same resource or memory location, particularly in hashing and networking. In hash tables, common collision resolution methods include chaining, which uses linked lists to store multiple elements, and open addressing, where probing sequences locate alternative slots. In networking, collision resolution protocols like Carrier Sense Multiple Access with Collision Detection (CSMA/CD) help manage packet collisions in Ethernet networks, improving data transmission efficiency. Effective collision resolution ensures system reliability and optimized data retrieval in computing environments.
Data Retrieval
Data retrieval in computer science involves the process of accessing and extracting data stored in databases, data warehouses, or other storage systems. Techniques such as SQL queries, indexing, and search algorithms optimize retrieval speed and accuracy. Efficient data retrieval is critical for applications involving big data analytics, real-time processing, and decision support systems. Advances in retrieval methods include the use of machine learning algorithms to enhance semantic search capabilities and improve user query interpretation.
Source and External Links
Difference between Indexing and Hashing in DBMS - GeeksforGeeks - Indexing uses a data structure to quickly locate and access data in a database by storing pointers to sorted data, improving retrieval and sorting; hashing uses a mathematical hash function to directly compute the storage location of data for faster query performance in specific cases, but does not maintain order and may have performance penalties with collisions and updates.
Hashing and Indexing Mainframe Data - Hashing is a specialized indexing technique that organizes data into buckets via mathematical functions for faster data access in certain IBM database products, while traditional indexes allow both rapid random lookups and efficient ordered data access.
Understanding hash indexes - Samuel Sorial's Blog - Hash indexes provide average O(1) lookup, insert, and delete times when keys are known exactly, but require careful design to handle collisions; indexing generally supports ordered data access and is more flexible for various query patterns.
FAQs
What is hashing in databases?
Hashing in databases is a technique that maps data to fixed-size hash values using hash functions for efficient data retrieval and storage.
What is indexing in databases?
Indexing in databases is a data structure technique that improves the speed of data retrieval operations by creating a sorted key-based reference to rows in a table.
How does hashing work compared to indexing?
Hashing uses a hash function to convert keys into fixed-size hash codes that directly map to storage locations, enabling constant-time average lookup. Indexing organizes data by creating auxiliary structures like B-trees to maintain sorted keys, supporting efficient range queries with logarithmic-time search.
What are the advantages of hashing over indexing?
Hashing provides constant-time average complexity O(1) for data retrieval, efficient storage with direct addressing, better performance on large datasets without sorted order, and reduced search times compared to indexing, which often requires O(log n) time due to tree or B-tree traversal.
What are the limitations of hashing and indexing?
Hashing limitations include collisions causing retrieval conflicts and uneven data distribution; indexing limitations involve increased storage overhead and slower performance on highly dynamic or large datasets.
When should you use hashing instead of indexing?
Use hashing instead of indexing when you require constant-time average lookup performance for exact-match queries on unique keys.
How do hashing and indexing impact query performance?
Hashing enables constant-time data retrieval by directly mapping keys to storage locations, significantly speeding up query performance for exact-match searches. Indexing organizes data structures, such as B-trees, to reduce search space and improve query speed for range and partial-match queries. Both techniques minimize disk I/O and CPU usage, enhancing overall query efficiency.