Hash Join efficiently matches rows by building a hash table on the smaller dataset, ideal for large, unsorted tables with equality conditions. Merge Join requires both input tables to be sorted and merges them by scanning through each dataset in order, offering advantages in range queries and sorted merges. Explore the key differences and performance considerations between Hash Join and Merge Join for optimized query execution.
Main Difference
Hash Join employs a hash table to match rows from two tables based on join keys, making it highly efficient for large, unsorted datasets. Merge Join requires both input tables to be sorted on the join key, performing a sequential merge to combine matching rows, which is optimal for already sorted or indexed data. Hash Join typically consumes more memory due to hash table construction, while Merge Join's performance depends on the sort operation cost. Database systems often choose Hash Join for equality joins and Merge Join for range or inequality joins where sorted data is beneficial.
Connection
Hash Join and Merge Join are connected as fundamental algorithms for performing join operations in relational databases, optimized for different data scenarios. Hash Join excels with large, unsorted datasets by building a hash table on one input to match rows efficiently, while Merge Join requires pre-sorted inputs and merges them in linear time, making it ideal for sorted or indexed data. Both approaches leverage different data organization techniques to improve query performance and reduce computational costs during join processing.
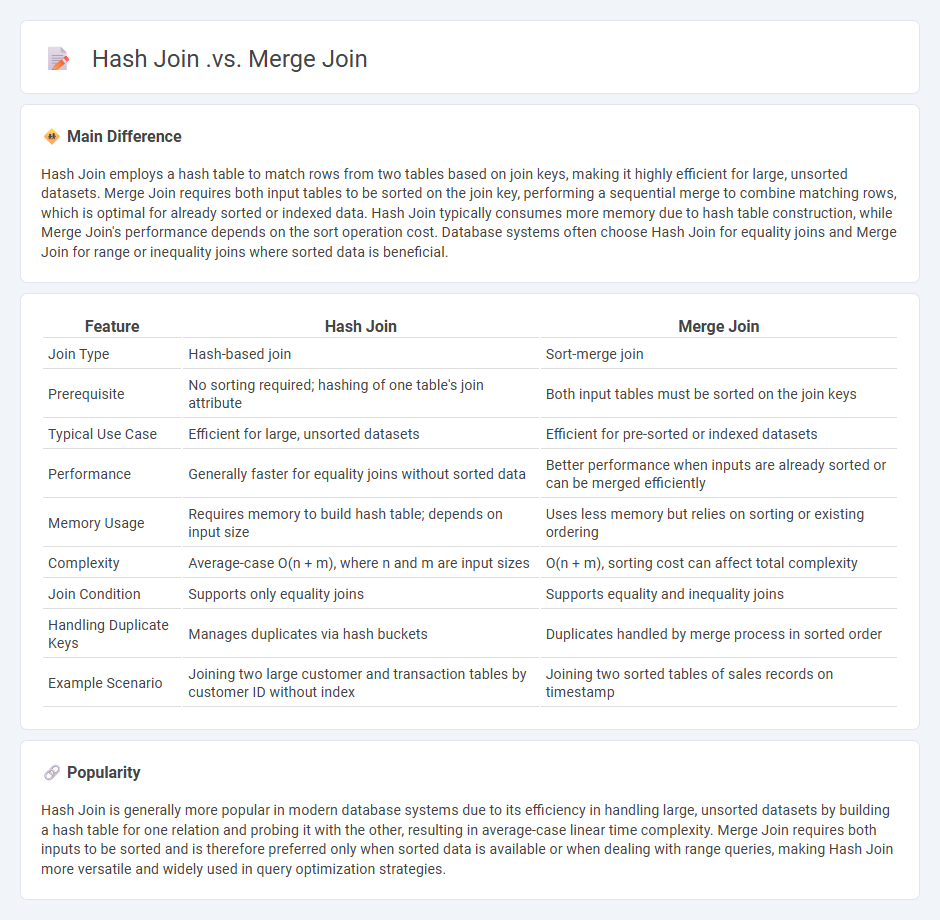
Comparison Table
| Feature | Hash Join | Merge Join |
|---|---|---|
| Join Type | Hash-based join | Sort-merge join |
| Prerequisite | No sorting required; hashing of one table's join attribute | Both input tables must be sorted on the join keys |
| Typical Use Case | Efficient for large, unsorted datasets | Efficient for pre-sorted or indexed datasets |
| Performance | Generally faster for equality joins without sorted data | Better performance when inputs are already sorted or can be merged efficiently |
| Memory Usage | Requires memory to build hash table; depends on input size | Uses less memory but relies on sorting or existing ordering |
| Complexity | Average-case O(n + m), where n and m are input sizes | O(n + m), sorting cost can affect total complexity |
| Join Condition | Supports only equality joins | Supports equality and inequality joins |
| Handling Duplicate Keys | Manages duplicates via hash buckets | Duplicates handled by merge process in sorted order |
| Example Scenario | Joining two large customer and transaction tables by customer ID without index | Joining two sorted tables of sales records on timestamp |
Hash Table
A hash table is a data structure that stores key-value pairs for efficient data retrieval, insertion, and deletion. It uses a hash function to convert keys into array indices, enabling near-constant time complexity for operations on average. Common collision resolution techniques include chaining and open addressing to handle cases where multiple keys map to the same index. Hash tables are widely used in databases, caching, and implementing associative arrays in programming languages like Python, Java, and C++.
Sorting
Sorting algorithms organize data into a specific order, improving search efficiency and data management in computing systems. Common techniques include quicksort, mergesort, and heapsort, each optimized for different data structures and sizes. Efficient sorting enhances performance in database query processing, graphics rendering, and machine learning algorithms. Advanced sorting methods leverage parallel processing and memory hierarchies to handle large-scale datasets in real-time applications.
Equi-Join
Equi-Join is a fundamental operation in relational databases where tables are combined based on equality between specified columns. This join compares columns with matching data values, typically primary keys and foreign keys, to produce result sets containing rows with equal attribute values. Optimizing equi-joins can significantly improve query performance in SQL engines by leveraging indexes on join columns. Commonly implemented in systems like MySQL, PostgreSQL, and SQL Server, equi-joins facilitate efficient data retrieval across normalized tables.
Memory Usage
Memory usage in computers refers to the amount of RAM actively utilized by programs and processes during operation. Efficient memory management enhances system performance and prevents bottlenecks caused by excessive paging or swapping. Modern operating systems use techniques like caching and virtual memory to optimize usage and allocate resources dynamically. Monitoring tools such as Task Manager in Windows or Activity Monitor in macOS provide real-time insights into memory consumption.
Performance Optimization
Performance optimization in computer systems involves improving hardware and software efficiency to reduce latency and increase throughput. Techniques include code profiling, algorithm refinement, parallel processing, and hardware acceleration using GPUs or FPGAs. Modern operating systems use dynamic resource allocation and caching strategies to enhance responsiveness and minimize bottlenecks. Performance metrics such as instructions per cycle (IPC), memory bandwidth, and latency are critical for evaluating optimization success.
Source and External Links
Nested Join vs Hash Join vs Merge Join in PostgreSQL - This article compares the efficiency and use cases of Hash Join and Merge Join in PostgreSQL, highlighting that Hash Join excels with larger tables and Merge Join performs best on sorted data.
Join Algorithms - This resource provides a detailed analysis of the costs associated with Hash Join and Merge Join algorithms, including the input/output operations and the efficiency under different data conditions.
How do nested loop, hash, and merge joins work - This video explains how Hash Join and Merge Join algorithms work, discussing their operational differences and when each is most efficient.
FAQs
What is a hash join?
A hash join is a database algorithm that efficiently combines two tables by hashing one table's join key into a hash table and then probing this hash table with the join key from the other table to find matching rows.
What is a merge join?
A merge join is a database operation that combines two sorted datasets by matching rows with equal keys, efficiently producing a joined result set.
How does a hash join work?
A hash join works by first building a hash table on the smaller input table using join keys, then probing this hash table with each row from the larger input table to find matching rows efficiently.
How does a merge join work?
A merge join works by sorting both input tables on the join key, then simultaneously scanning them to match rows with equal keys, efficiently producing joined results.
When should you use a hash join?
Use a hash join when joining large, unsorted tables on equality conditions, especially when no indexes exist on the join keys, to optimize performance by building a hash table on the smaller input.
When is a merge join more efficient?
A merge join is more efficient when both input datasets are pre-sorted on the join key, allowing linear-time comparison without additional sorting or hashing overhead.
What are the main differences between hash join and merge join?
Hash join uses a hash table to match join keys, ideal for unsorted inputs and equi-joins; merge join requires both inputs to be sorted on join keys, performing efficiently on large, pre-sorted datasets with range or equality conditions.