Normalization organizes database tables to minimize redundancy and ensure data integrity, typically through splitting data into multiple related tables following rules like 1NF, 2NF, and 3NF. Denormalization intentionally introduces redundancy by combining tables or adding redundant data to improve read performance and reduce complex joins in high-traffic systems. Explore the detailed benefits and trade-offs between normalization and denormalization for effective database design.
Main Difference
Normalization organizes database tables to minimize redundancy and improve data integrity by dividing data into related tables using primary and foreign keys. Denormalization combines tables to reduce complex joins, enhancing query performance and simplifying data retrieval at the cost of increased redundancy. Normalization follows forms such as 1NF, 2NF, and 3NF, while denormalization strategically reverses some of these steps for optimization. The choice depends on balancing update efficiency against read efficiency in database design.
Connection
Normalization organizes database tables to reduce redundancy and improve data integrity by dividing data into related tables, while denormalization intentionally combines tables to optimize query performance and simplify data retrieval. Both processes manipulate the database schema to balance between data consistency and efficient access, depending on application requirements. Understanding when to apply normalization or denormalization is crucial for database design, as it impacts storage, speed, and maintenance.
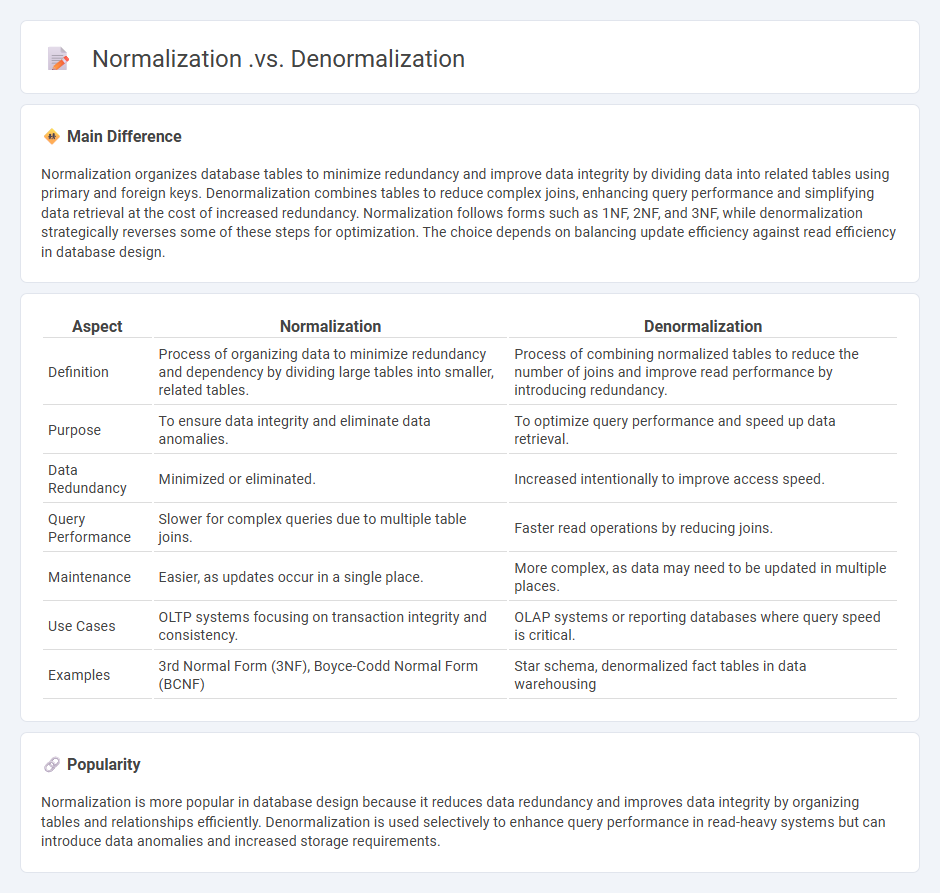
Comparison Table
| Aspect | Normalization | Denormalization |
|---|---|---|
| Definition | Process of organizing data to minimize redundancy and dependency by dividing large tables into smaller, related tables. | Process of combining normalized tables to reduce the number of joins and improve read performance by introducing redundancy. |
| Purpose | To ensure data integrity and eliminate data anomalies. | To optimize query performance and speed up data retrieval. |
| Data Redundancy | Minimized or eliminated. | Increased intentionally to improve access speed. |
| Query Performance | Slower for complex queries due to multiple table joins. | Faster read operations by reducing joins. |
| Maintenance | Easier, as updates occur in a single place. | More complex, as data may need to be updated in multiple places. |
| Use Cases | OLTP systems focusing on transaction integrity and consistency. | OLAP systems or reporting databases where query speed is critical. |
| Examples | 3rd Normal Form (3NF), Boyce-Codd Normal Form (BCNF) | Star schema, denormalized fact tables in data warehousing |
Data Redundancy
Data redundancy in computer systems refers to the unnecessary duplication of data across multiple storage locations or databases. This can lead to increased storage costs, data inconsistency, and more complex data management processes. Efficient database design techniques like normalization help minimize redundancy by organizing data into related tables. Cloud storage solutions and backup systems often intentionally use controlled redundancy to enhance data recovery and fault tolerance.
Data Integrity
Data integrity in computer systems ensures the accuracy, consistency, and reliability of data throughout its lifecycle, from creation to storage and retrieval. Techniques such as checksums, hashing algorithms, and error-correcting codes validate and protect data against corruption, unauthorized modification, and loss. Maintaining data integrity is critical in databases, cloud computing, and cybersecurity to support decision-making, compliance, and operational efficiency. Advances in blockchain technology provide decentralized solutions to enhance data trustworthiness and tamper resistance in digital environments.
Query Performance
Query performance in computer systems is crucial for optimizing database efficiency and user experience. High-performing queries reduce response time by efficiently accessing and processing data using indexes, caching, and query optimization techniques. Modern database management systems like MySQL, PostgreSQL, and Oracle implement cost-based optimizers to enhance query execution plans. Monitoring tools such as SQL Profiler and EXPLAIN ANALYZE help identify bottlenecks and improve overall query speed.
Storage Efficiency
Storage efficiency in computer systems measures the effectiveness of data storage mechanisms in maximizing capacity while minimizing waste and redundancy. Advances in data compression algorithms, such as LZ77 and Huffman coding, enhance storage efficiency by reducing file sizes without compromising quality. Modern storage solutions like solid-state drives (SSDs) and cloud storage platforms optimize space utilization through techniques including wear leveling and deduplication. Effective storage management directly impacts system performance, cost reduction, and data accessibility across enterprise environments.
Use Case Scenarios
Use case scenarios in computer systems outline specific interactions between users and software to achieve defined goals, enhancing system design and usability. Examples include user authentication processes, data retrieval tasks, and error handling workflows, which help developers anticipate user needs and system responses. Implementing detailed use case scenarios facilitates effective requirement gathering, reduces development risks, and improves user experience. Industry standards like UML promote structured representation of these scenarios for better project communication.
Source and External Links
Difference between Normalization and Denormalization - Normalization reduces data redundancy and maintains data integrity by increasing the number of tables, while denormalization adds redundancy to combine tables for faster query execution at the cost of data integrity and increased storage use.
Normalization vs. Denormalization in Databases - CodiLime - Normalization ensures data consistency and easier maintenance by minimizing redundancy but can slow reads, whereas denormalization improves read performance and query simplicity by adding redundancy, risking inconsistencies.
Denormalized vs. Normalized Data - Pure Storage Blog - Denormalization strategically introduces redundancy using modern techniques like materialized views and data pipelines to optimize query speed and analytical processing, contrasting with normalization's focus on minimizing redundancy for data integrity.
FAQs
What is normalization in databases?
Normalization in databases is the process of organizing data to minimize redundancy and ensure data integrity by dividing tables into smaller, related tables following normal forms such as 1NF, 2NF, and 3NF.
What is denormalization in databases?
Denormalization in databases is the process of intentionally introducing redundancy by combining tables or duplicating data to improve read performance and reduce complex joins.
How do normalization and denormalization differ?
Normalization reduces data redundancy by organizing data into related tables, while denormalization combines tables to improve query performance at the expense of redundancy.
What are the benefits of normalization?
Normalization reduces data redundancy, improves data integrity, enhances database consistency, simplifies database maintenance, and optimizes query performance.
What are the advantages of denormalization?
Denormalization improves query performance by reducing the number of joins, enhances read speed for reporting and analytics, simplifies complex queries, and increases data retrieval efficiency in read-heavy databases.
When should you use normalization or denormalization?
Use normalization to reduce data redundancy and improve data integrity in transactional databases; use denormalization to enhance query performance and speed in read-heavy systems or data warehousing.
How does normalization impact database performance?
Normalization reduces data redundancy and improves data integrity, which enhances query efficiency and update speed, but excessive normalization can increase the number of joins, potentially slowing complex queries.