Pipelining enhances CPU performance by breaking down instruction execution into multiple stages, allowing overlapping of operations and increasing instruction throughput. Superscalar execution further improves processing speed by enabling multiple instructions to be issued and executed simultaneously within a single clock cycle using multiple execution units. Discover more about how these architectures revolutionize computational efficiency and impact modern processor design.
Main Difference
Pipelining breaks down the execution process into sequential stages, allowing multiple instructions to be processed simultaneously at different phases, which increases instruction throughput. Superscalar execution involves multiple execution units that dispatch and complete more than one instruction per clock cycle, enabling parallel execution of instructions. Pipelining focuses on overlapping instruction execution stages, while superscalar designs focus on executing multiple instructions in parallel within the same stage. Both techniques improve CPU performance but address different aspects of instruction processing.
Connection
Pipelining enhances CPU performance by breaking instruction execution into discrete stages, allowing multiple instructions to overlap in execution. Superscalar execution increases throughput further by dispatching multiple instructions simultaneously across multiple pipelines. Together, they optimize instruction-level parallelism, significantly improving processing speed and efficiency.
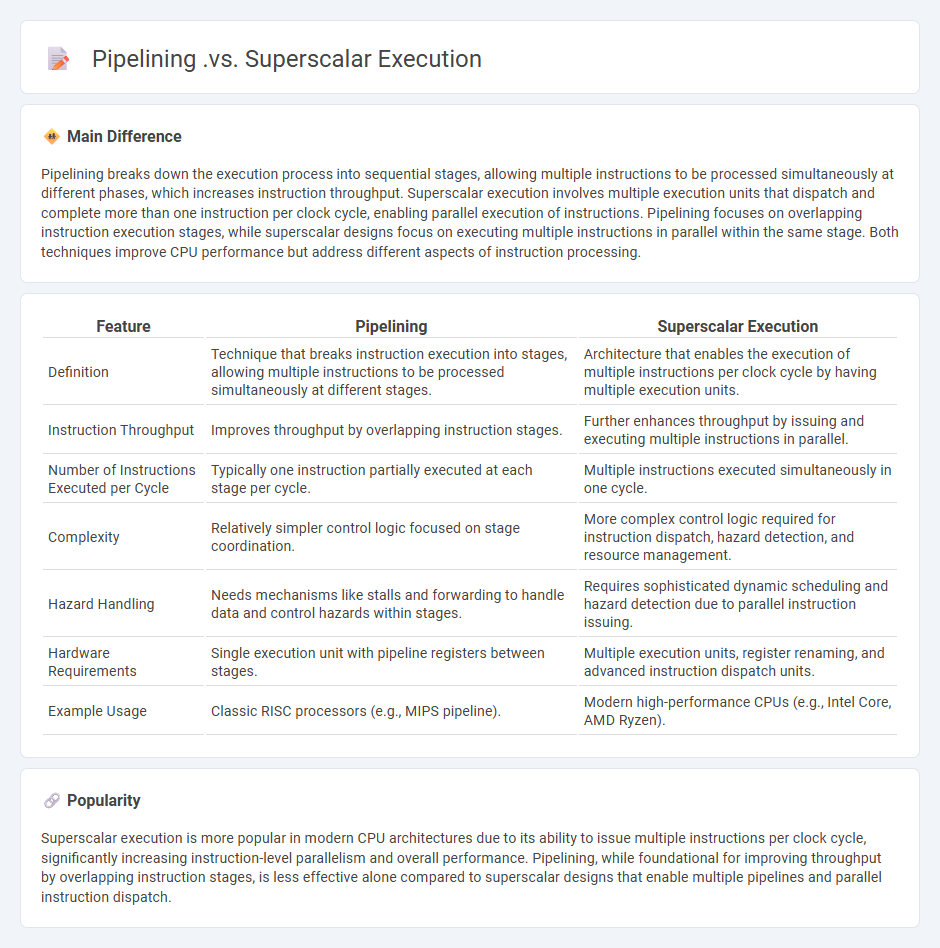
Comparison Table
| Feature | Pipelining | Superscalar Execution |
|---|---|---|
| Definition | Technique that breaks instruction execution into stages, allowing multiple instructions to be processed simultaneously at different stages. | Architecture that enables the execution of multiple instructions per clock cycle by having multiple execution units. |
| Instruction Throughput | Improves throughput by overlapping instruction stages. | Further enhances throughput by issuing and executing multiple instructions in parallel. |
| Number of Instructions Executed per Cycle | Typically one instruction partially executed at each stage per cycle. | Multiple instructions executed simultaneously in one cycle. |
| Complexity | Relatively simpler control logic focused on stage coordination. | More complex control logic required for instruction dispatch, hazard detection, and resource management. |
| Hazard Handling | Needs mechanisms like stalls and forwarding to handle data and control hazards within stages. | Requires sophisticated dynamic scheduling and hazard detection due to parallel instruction issuing. |
| Hardware Requirements | Single execution unit with pipeline registers between stages. | Multiple execution units, register renaming, and advanced instruction dispatch units. |
| Example Usage | Classic RISC processors (e.g., MIPS pipeline). | Modern high-performance CPUs (e.g., Intel Core, AMD Ryzen). |
Instruction Throughput
Instruction throughput measures the number of instructions a computer processor can execute per unit of time, often expressed in instructions per cycle (IPC) or instructions per second. High throughput indicates efficient processor design, maximizing parallelism through techniques such as pipelining, superscalar execution, and out-of-order execution. Modern CPUs like the Intel Core i9-13900K achieve instruction throughputs exceeding 6 IPC under optimal conditions. Optimizing instruction throughput is crucial for enhancing overall system performance in applications ranging from gaming to scientific computation.
Parallelism
Parallelism in computer architecture involves dividing a task into sub-tasks that are processed simultaneously across multiple processors or cores. This technique enhances computational speed and efficiency by allowing concurrent execution of instructions, reducing the overall processing time. Common forms of parallelism include data parallelism, where identical operations are performed on different data sets, and task parallelism, where distinct tasks are executed simultaneously. Modern processors leverage parallelism through multi-core CPUs, GPUs, and distributed computing systems to optimize performance in applications like scientific simulations and large-scale data analysis.
Pipeline Stages
Pipeline stages in computer architecture refer to the distinct steps a processor executes to complete an instruction, enhancing overall CPU throughput by overlapping these phases. Common pipeline stages include instruction fetch (IF), instruction decode (ID), execute (EX), memory access (MEM), and write-back (WB). Each stage processes a separate instruction simultaneously, allowing modern processors like the Intel Core i7 to achieve higher instruction-level parallelism. Efficient pipeline design reduces latency and improves clock cycle efficiency in complex computing tasks.
Multiple Issue
Computers often face multiple issues, including hardware failures, software conflicts, and malware infections that degrade performance and stability. Common hardware problems involve hard drive crashes, faulty RAM, and overheating components causing system shutdowns. Software-related issues frequently stem from corrupted files, incompatible updates, and driver errors, resulting in frequent crashes or slow response times. Efficient diagnosis and timely maintenance, such as using antivirus programs and updating drivers, can significantly extend computer lifespan and ensure smooth operation.
Data Hazards
Data hazards in computer architecture occur when instructions that exhibit data dependencies are executed out of order, potentially leading to incorrect results. These hazards are categorized into three types: read-after-write (RAW), write-after-read (WAR), and write-after-write (WAW), each affecting pipeline performance differently. Techniques such as forwarding, pipeline stalling, and dynamic scheduling are employed to mitigate data hazards and maintain instruction-level parallelism. Modern processors leverage advanced hazard detection and resolution mechanisms to optimize execution efficiency and minimize pipeline stalls.
Source and External Links
## Set 1Superscalar Processor - A superscalar processor executes multiple instructions in a single clock cycle, exploiting instruction-level parallelism by dispatching instructions to multiple execution units.
## Set 2Pipelining, Scalar & Superscalar Execution - This document discusses how pipelining and superscalar techniques enhance processor performance by increasing throughput and reducing latency.
## Set 3Difference Between Pipelining and Super Scalar Processor - This essay explains the differences between pipelining, which divides operations into stages for sequential execution, and superscalar execution, which executes multiple instructions per cycle.
FAQs
What is pipelining in computer architecture?
Pipelining in computer architecture is a technique that divides instruction execution into separate stages, allowing multiple instructions to overlap and improve CPU throughput.
What is superscalar execution?
Superscalar execution is a CPU architecture technique that allows multiple instructions to be issued and executed simultaneously within a single clock cycle by utilizing multiple execution units.
How does pipelining improve CPU performance?
Pipelining improves CPU performance by executing multiple instruction phases concurrently, increasing instruction throughput and reducing the overall cycle time per instruction.
How do superscalar processors handle multiple instructions?
Superscalar processors handle multiple instructions by simultaneously dispatching and executing several instructions in parallel using multiple execution units, leveraging instruction-level parallelism within a single clock cycle.
What are the main differences between pipelining and superscalar execution?
Pipelining divides instruction execution into sequential stages allowing one instruction per clock cycle, while superscalar execution issues multiple instructions simultaneously per clock cycle using multiple execution units.
Can pipelining and superscalar techniques be used together?
Pipelining and superscalar techniques are combined in modern CPUs to execute multiple instructions simultaneously and increase overall instruction throughput.
What are the challenges in implementing pipelining and superscalar architectures?
Challenges in implementing pipelining include handling data hazards, control hazards, and structural hazards that cause stalls and reduce instruction throughput. Superscalar architectures face difficulties in instruction-level parallelism extraction, complex dependency checking, increased hardware complexity for multiple issue units, and efficient branch prediction to avoid pipeline flushes.