Biostatistics applies statistical techniques to analyze data from biological research, focusing on hypothesis testing, experimental design, and data interpretation in fields like epidemiology and clinical trials. Bioinformatics combines biology, computer science, and information technology to manage and analyze large-scale biological data, such as genomic sequences and protein structures. Explore detailed distinctions and applications to see how each field drives advancements in biological sciences.
Main Difference
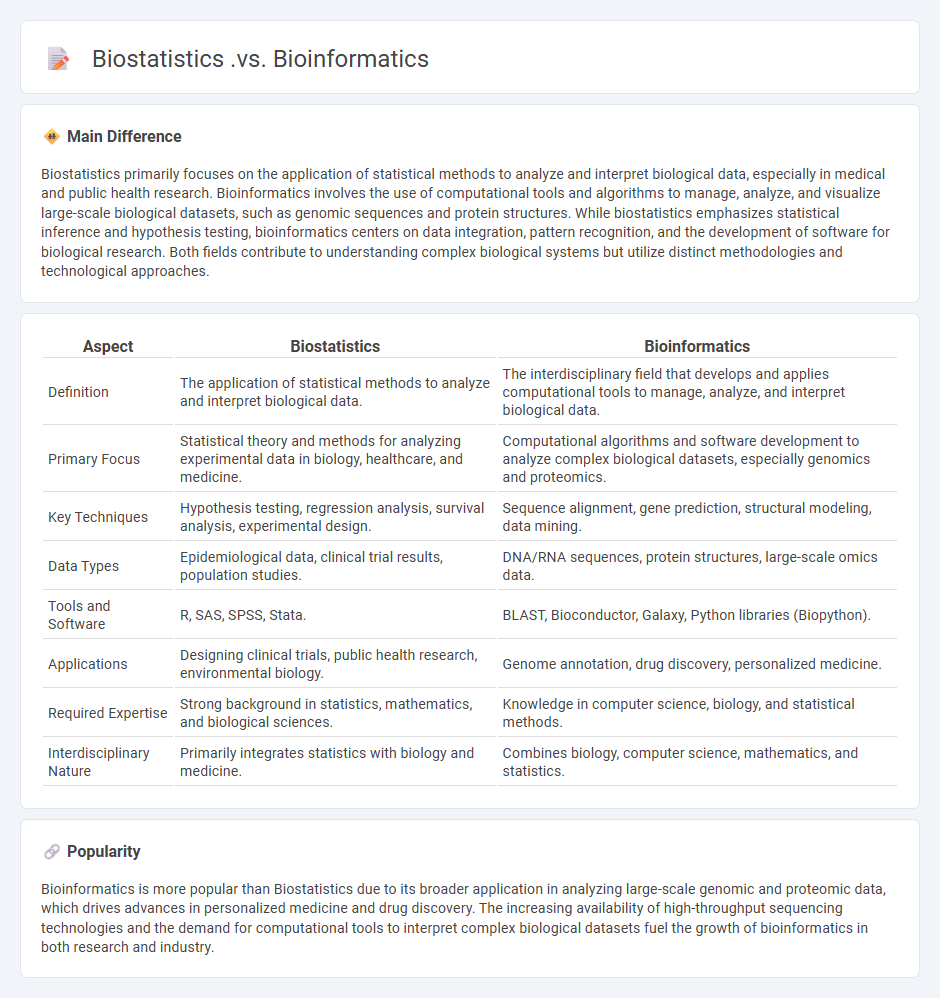
Biostatistics primarily focuses on the application of statistical methods to analyze and interpret biological data, especially in medical and public health research. Bioinformatics involves the use of computational tools and algorithms to manage, analyze, and visualize large-scale biological datasets, such as genomic sequences and protein structures. While biostatistics emphasizes statistical inference and hypothesis testing, bioinformatics centers on data integration, pattern recognition, and the development of software for biological research. Both fields contribute to understanding complex biological systems but utilize distinct methodologies and technological approaches.
Connection
Biostatistics and bioinformatics are interconnected through their shared use of statistical methods to analyze complex biological data, particularly in genomics and proteomics. Biostatistics provides the foundational tools for data modeling, hypothesis testing, and interpretation, while bioinformatics applies these techniques to manage and interpret large-scale biological datasets using computational algorithms. This synergy enables the extraction of meaningful insights from high-throughput experiments, driving advancements in personalized medicine and biological research.
Comparison Table
| Aspect | Biostatistics | Bioinformatics |
|---|---|---|
| Definition | The application of statistical methods to analyze and interpret biological data. | The interdisciplinary field that develops and applies computational tools to manage, analyze, and interpret biological data. |
| Primary Focus | Statistical theory and methods for analyzing experimental data in biology, healthcare, and medicine. | Computational algorithms and software development to analyze complex biological datasets, especially genomics and proteomics. |
| Key Techniques | Hypothesis testing, regression analysis, survival analysis, experimental design. | Sequence alignment, gene prediction, structural modeling, data mining. |
| Data Types | Epidemiological data, clinical trial results, population studies. | DNA/RNA sequences, protein structures, large-scale omics data. |
| Tools and Software | R, SAS, SPSS, Stata. | BLAST, Bioconductor, Galaxy, Python libraries (Biopython). |
| Applications | Designing clinical trials, public health research, environmental biology. | Genome annotation, drug discovery, personalized medicine. |
| Required Expertise | Strong background in statistics, mathematics, and biological sciences. | Knowledge in computer science, biology, and statistical methods. |
| Interdisciplinary Nature | Primarily integrates statistics with biology and medicine. | Combines biology, computer science, mathematics, and statistics. |
Data Types
Data types define the kind of data a variable can hold in programming languages, such as integers, floating-point numbers, strings, booleans, and arrays. Integer types store whole numbers, while floating-point types handle decimal values with precision. Strings consist of sequences of characters used for text representation, and booleans represent logical values TRUE or FALSE. Arrays and other composite types group multiple values of the same or different types, facilitating structured data storage.
Statistical Methods
Statistical methods encompass a wide range of techniques used to collect, analyze, interpret, and present data effectively in various fields such as economics, medicine, and engineering. Key methods include descriptive statistics, inferential statistics, regression analysis, hypothesis testing, and Bayesian inference, each facilitating different aspects of understanding data patterns and relationships. Advanced statistical software like R, SAS, and SPSS significantly enhance the accuracy and efficiency of data analysis processes. Mastery of statistical methods enables researchers to draw meaningful conclusions, support decision-making, and predict future trends based on empirical evidence.
Computational Tools
Computational tools such as MATLAB, Python libraries (NumPy, SciPy), and R provide powerful capabilities for data analysis, simulation, and modeling in various scientific and engineering fields. These tools optimize complex calculations, enabling researchers to solve differential equations, perform statistical analysis, and implement machine learning algorithms efficiently. High-performance computing platforms like GPUs and cloud-based services (AWS, Google Cloud) further enhance computational speed and scalability. Open-source software communities continually contribute to the advancement of computational tools, ensuring up-to-date resources and extensive documentation.
Experimental Design
Experimental design structures research to systematically test hypotheses by controlling variables and eliminating bias. It involves selecting appropriate sample sizes, randomizing participants, and establishing control and experimental groups to ensure data validity. Key methods include factorial, randomized block, and crossover designs, which optimize reliability and replicate real-world conditions. Proper experimental design enhances statistical power and supports accurate conclusions in scientific studies.
Data Interpretation
Data interpretation involves analyzing statistical figures, charts, and graphs to extract meaningful insights. Accurate interpretation requires understanding the context, identifying trends, and recognizing anomalies within datasets. Common tools include Excel, Python libraries like Pandas and Matplotlib, and data visualization software such as Tableau. Effective data interpretation supports decision-making in fields ranging from business analytics to scientific research.
Source and External Links
The Difference Between Biostatistics and Bioinformatics - Biostatistics focuses on applying statistical methods to biological and health data, including study design and inference, while bioinformatics uses computational tools and algorithms to analyze molecular-level biological data such as genomics and proteomics.
Biostatistics vs. Bioinformatics: Definitions and Differences - Indeed - Biostatistics emphasizes statistical principles and applied data analysis in biology and health, whereas bioinformatics is interdisciplinary, combining biology, statistics, and computer programming to develop new computational tools for complex biological data.
Bioinformatics vs Biostatistics - A 2024 Analysis of Biological Data ... - Bioinformatics requires strong programming, algorithm development, and database management skills to interpret genomic data, while biostatistics applies rigorous statistical modeling and inference to guide evidence-based decisions in biology and public health.
FAQs
What is biostatistics?
Biostatistics is the application of statistical methods to analyze data and solve problems in biology, medicine, and public health.
What is bioinformatics?
Bioinformatics is the interdisciplinary field that develops methods and software tools for understanding biological data, particularly large-scale genomic and proteomic sequences.
How do biostatistics and bioinformatics differ?
Biostatistics focuses on the development and application of statistical methods to analyze biological data, while bioinformatics emphasizes the use of computational tools and algorithms to interpret and manage complex biological information, such as genomic sequences.
What are the main applications of biostatistics?
Biostatistics is primarily applied in medical research, public health studies, clinical trials, epidemiology, genetics, environmental health, and health policy evaluation.
What are the key uses of bioinformatics?
Bioinformatics is primarily used for genome sequencing and annotation, predicting protein structures and functions, analyzing genetic variations, identifying disease biomarkers, drug discovery, and facilitating personalized medicine.
What skills are needed for biostatistics and bioinformatics?
Proficiency in statistics, probability, and mathematical modeling; expertise in programming languages like R, Python, and SAS; knowledge of molecular biology and genetics; experience with data analysis, machine learning, and database management; strong skills in data visualization and interpretation; and familiarity with software tools such as Bioconductor and Hadoop.
How do biostatistics and bioinformatics complement each other?
Biostatistics provides statistical methods for designing experiments and analyzing biological data, while bioinformatics develops computational tools to manage and interpret large-scale biological datasets, together enabling comprehensive insights in biomedical research.