Control hazards occur during instruction fetching when branch predictions lead to incorrect paths, causing pipeline stalls. Data hazards arise from dependencies between instructions, resulting in delays to ensure correct data usage. Explore further to understand how processors mitigate these hazards for optimized performance.
Main Difference
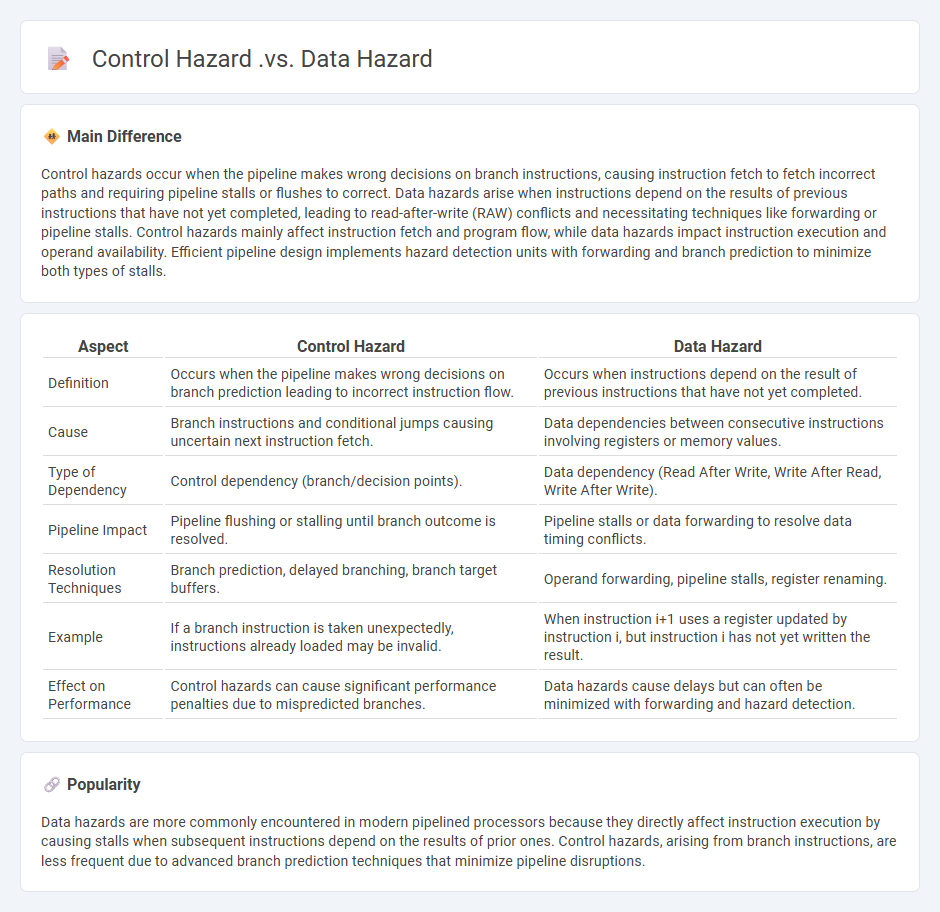
Control hazards occur when the pipeline makes wrong decisions on branch instructions, causing instruction fetch to fetch incorrect paths and requiring pipeline stalls or flushes to correct. Data hazards arise when instructions depend on the results of previous instructions that have not yet completed, leading to read-after-write (RAW) conflicts and necessitating techniques like forwarding or pipeline stalls. Control hazards mainly affect instruction fetch and program flow, while data hazards impact instruction execution and operand availability. Efficient pipeline design implements hazard detection units with forwarding and branch prediction to minimize both types of stalls.
Connection
Control hazards and data hazards both disrupt the smooth execution of instructions in a CPU pipeline by causing stalls or delays. Control hazards arise from branch instructions that alter the program flow unpredictably, leading to pipeline flushes, while data hazards occur when instructions depend on the results of previous instructions not yet completed, resulting in data forwarding or stalls. Efficient pipeline design and hazard detection mechanisms are essential to mitigate these hazards and maintain high instruction throughput.
Comparison Table
| Aspect | Control Hazard | Data Hazard |
|---|---|---|
| Definition | Occurs when the pipeline makes wrong decisions on branch prediction leading to incorrect instruction flow. | Occurs when instructions depend on the result of previous instructions that have not yet completed. |
| Cause | Branch instructions and conditional jumps causing uncertain next instruction fetch. | Data dependencies between consecutive instructions involving registers or memory values. |
| Type of Dependency | Control dependency (branch/decision points). | Data dependency (Read After Write, Write After Read, Write After Write). |
| Pipeline Impact | Pipeline flushing or stalling until branch outcome is resolved. | Pipeline stalls or data forwarding to resolve data timing conflicts. |
| Resolution Techniques | Branch prediction, delayed branching, branch target buffers. | Operand forwarding, pipeline stalls, register renaming. |
| Example | If a branch instruction is taken unexpectedly, instructions already loaded may be invalid. | When instruction i+1 uses a register updated by instruction i, but instruction i has not yet written the result. |
| Effect on Performance | Control hazards can cause significant performance penalties due to mispredicted branches. | Data hazards cause delays but can often be minimized with forwarding and hazard detection. |
Pipeline Stalling
Pipeline stalling occurs in computer architecture when the next instruction in the pipeline cannot execute in the following clock cycle, halting progress and reducing CPU efficiency. Causes include data hazards, control hazards, and structural hazards, each disrupting instruction flow at different pipeline stages. Techniques such as forwarding, branch prediction, and pipeline interleaving help mitigate stalls by allowing earlier instructions to resolve dependencies or by reorganizing execution order. Modern processors in Intel Core and AMD Ryzen series implement advanced out-of-order execution and speculative execution to minimize the impact of pipeline stalls and maximize throughput.
Data Dependency
Data dependency in computer architecture refers to the relationship between instructions where one instruction depends on the data result of a previous instruction. This phenomenon impacts instruction scheduling and pipeline efficiency in modern CPUs, causing hazards such as read-after-write (RAW), write-after-read (WAR), and write-after-write (WAW). Techniques like out-of-order execution, register renaming, and speculative execution are deployed to mitigate performance degradation caused by data dependencies. Understanding data dependencies is crucial for optimizing compiler design and improving processor throughput.
Branch Prediction
Branch prediction in computer architecture improves processor efficiency by guessing the outcome of conditional instructions before they are resolved. Modern processors use dynamic branch predictors, such as the two-level adaptive predictor or the perceptron predictor, to achieve accuracy rates exceeding 95%. Accurate branch prediction reduces pipeline stalls and increases instruction-level parallelism, significantly enhancing overall CPU performance. Research shows that advanced predictors can improve execution speed by up to 30% in high-performance computing applications.
Instruction Fetch
Instruction fetch is a critical step in the CPU pipeline where the processor retrieves the next instruction to execute from memory, typically stored in the instruction cache or main memory. This process relies on the program counter (PC), which holds the address of the upcoming instruction, ensuring sequential execution unless altered by control flow instructions like jumps or branches. Efficient instruction fetch mechanisms reduce latency and improve processing speed by prefetching instructions and minimizing cache misses. Modern CPUs use techniques such as pipeline fetching and branch prediction to maintain a steady flow of instructions to the execution units.
Forwarding (Bypassing)
Forwarding, also known as bypassing, is a technique used in computer architecture to reduce data hazards within pipelines by rerouting data directly from one pipeline stage to another without writing to and reading from registers. This method enhances CPU efficiency by minimizing pipeline stalls and improving instruction throughput. Forwarding typically occurs between the execution and decode stages in processors such as those implementing RISC architectures like MIPS or ARM. By utilizing hardware comparators and multiplexers, forwarding swiftly resolves data dependencies, enabling faster instruction execution.
Source and External Links
### Set 1Pipeline Hazards - Control hazards occur due to branching instructions, causing delays in instruction fetching until the branch destination is known, whereas data hazards arise from dependencies between instructions.
### Set 2Pipeline Hazards - Control hazards are associated with branching instructions, while data hazards occur when an instruction depends on the outcome of a previous one.
### Set 3LECTURE 9 Pipeline Hazards - Control hazards involve branch instructions, whereas data hazards result from dependencies between instructions, such as when a source register depends on a prior instruction's write operation.
FAQs
What is a hazard in computer architecture?
A hazard in computer architecture is a condition that causes delays or incorrect execution in a pipelined processor due to resource conflicts, data dependencies, or control flow changes.
What is a control hazard?
A control hazard, also known as a branch hazard, occurs in pipelined processors when the pipeline makes wrong decisions on branching, causing instruction fetches to be incorrect and requiring pipeline flushing or stalling to resolve.
What is a data hazard?
A data hazard occurs in CPU pipelines when an instruction depends on the result of a previous instruction that has not yet completed, causing a delay in execution.
How do control hazards affect instruction execution?
Control hazards cause pipeline stalls or flushes by disrupting instruction flow during branch decisions, decreasing CPU instruction throughput and increasing latency.
How are data hazards detected and resolved?
Data hazards are detected using hardware mechanisms like scoreboards or scoreboard-free techniques such as hazard detection units that monitor instruction dependencies. They are resolved through techniques like pipeline stalling, forwarding (data bypassing), and dynamic scheduling to ensure correct instruction execution order without data corruption.
What techniques reduce control hazards?
Branch prediction, delayed branching, and pipeline stalling effectively reduce control hazards.
What techniques reduce data hazards?
Techniques that reduce data hazards include forwarding (data bypassing), pipeline stalling (inserting bubbles), instruction reordering, and using hazard detection units.