Strong consistency guarantees that every read receives the most recent write, ensuring immediate synchronization across distributed systems. Eventual consistency allows for temporary discrepancies, with data replicas converging over time to achieve uniformity. Explore the trade-offs between these models to optimize your distributed database strategy.
Main Difference
Strong consistency ensures that all read operations return the most recent write, providing a single, up-to-date view of the data across distributed systems. Eventual consistency allows reads to return stale data temporarily but guarantees that all replicas will converge to the same value over time. Strong consistency is critical for systems requiring immediate accuracy like financial transactions, while eventual consistency suits distributed databases prioritizing availability and partition tolerance. The trade-off involves latency and system performance, where strong consistency generally incurs higher delays compared to eventual consistency.
Connection
Strong consistency ensures that all read operations return the most recent write, providing immediate synchronization across distributed systems, while eventual consistency allows for temporary discrepancies but guarantees data convergence over time. Both models address data synchronization challenges in distributed databases, with trade-offs between latency, availability, and consistency defined by the CAP theorem. Understanding their relationship helps optimize system design by balancing strict consistency requirements and performance scalability.
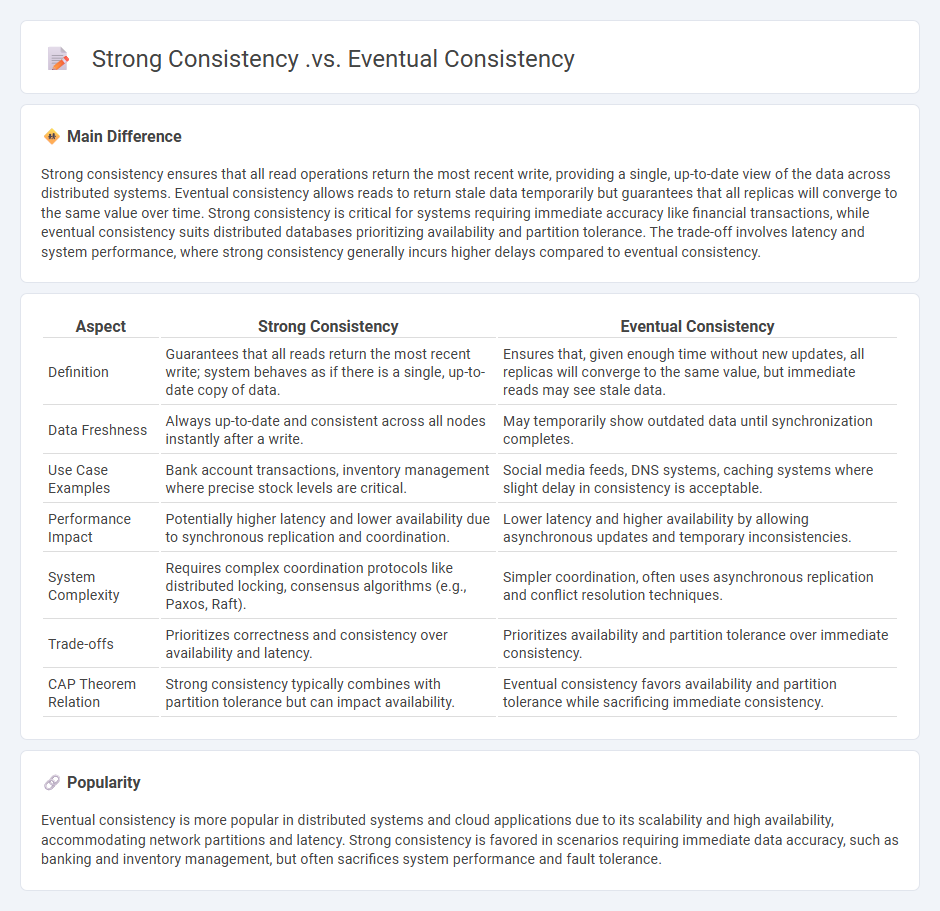
Comparison Table
| Aspect | Strong Consistency | Eventual Consistency |
|---|---|---|
| Definition | Guarantees that all reads return the most recent write; system behaves as if there is a single, up-to-date copy of data. | Ensures that, given enough time without new updates, all replicas will converge to the same value, but immediate reads may see stale data. |
| Data Freshness | Always up-to-date and consistent across all nodes instantly after a write. | May temporarily show outdated data until synchronization completes. |
| Use Case Examples | Bank account transactions, inventory management where precise stock levels are critical. | Social media feeds, DNS systems, caching systems where slight delay in consistency is acceptable. |
| Performance Impact | Potentially higher latency and lower availability due to synchronous replication and coordination. | Lower latency and higher availability by allowing asynchronous updates and temporary inconsistencies. |
| System Complexity | Requires complex coordination protocols like distributed locking, consensus algorithms (e.g., Paxos, Raft). | Simpler coordination, often uses asynchronous replication and conflict resolution techniques. |
| Trade-offs | Prioritizes correctness and consistency over availability and latency. | Prioritizes availability and partition tolerance over immediate consistency. |
| CAP Theorem Relation | Strong consistency typically combines with partition tolerance but can impact availability. | Eventual consistency favors availability and partition tolerance while sacrificing immediate consistency. |
Data Synchronization
Data synchronization in computing ensures consistency and uniformity of data across multiple devices or systems by continuously updating and harmonizing changes. Techniques like two-way synchronization and conflict resolution algorithms maintain data integrity in real-time environments such as cloud storage, distributed databases, and mobile applications. Key technologies enabling efficient data synchronization include APIs, synchronization frameworks like Microsoft Sync Framework, and protocols such as SyncML. Effective synchronization reduces data redundancy, prevents conflicts, and supports seamless user experiences in interconnected systems.
Consensus Protocols
Consensus protocols are critical mechanisms in distributed computing that ensure all participating nodes agree on a single data value, maintaining system consistency despite failures or network partitions. Prominent examples include Paxos, Raft, and Practical Byzantine Fault Tolerance (PBFT), each designed to handle specific fault tolerance and performance requirements. These protocols are extensively employed in blockchain networks, distributed databases, and fault-tolerant systems to guarantee data integrity and coordination among replicas. Advances in consensus algorithms focus on improving scalability, reducing latency, and enhancing security in decentralized environments.
Latency Trade-offs
Latency trade-offs in computer systems involve balancing speed and resource utilization to optimize performance. High-frequency processors reduce latency but often increase power consumption and heat production, impacting system efficiency. Memory hierarchy designs address latency by using faster, smaller caches closer to the CPU while relying on slower, larger main memory. Network latency considerations influence data center architecture, where reducing physical distance between servers and clients minimizes delay for real-time applications.
Availability
Availability in computer systems measures the proportion of time a system remains operational and accessible to users, typically expressed as a percentage over a specific period. High availability targets, such as 99.999% uptime (known as "five nines"), correspond to fewer minutes of downtime annually, ensuring continuous access to critical applications and services. Techniques like redundancy, failover clustering, and load balancing are commonly employed to maximize system availability. Monitoring tools like Nagios and Zabbix help maintain availability by detecting and alerting about potential failures in real-time.
Conflict Resolution
Conflict resolution in computer systems refers to techniques used to manage and resolve competing operations or data inconsistencies in distributed computing environments. It involves algorithms such as consensus protocols, version vectors, and locking mechanisms to ensure data integrity and system reliability. Effective conflict resolution enhances performance in databases, network communication, and collaborative applications by minimizing data loss and ensuring consistency. Emerging methods leverage machine learning to predict and mitigate conflicts proactively in real-time systems.
Source and External Links
Strong vs. Eventual Consistency in System Design - GeeksforGeeks - Strong consistency guarantees that all reads return the most recent write immediately, ensuring synchronized data with higher latency and lower availability during network partitions, suitable for systems like financial transactions; eventual consistency allows temporary inconsistencies but ensures all replicas converge eventually, providing higher availability and scalability with lower latency, used in social media feeds and caching systems.
Strong Consistency vs Eventual Consistency - System Design School - Strong consistency ensures reads always return the latest writes with ACID guarantees but suffers from limited scalability and higher latency, while eventual consistency allows delayed visibility of writes, enabling better scalability and availability but at the cost of temporary stale data and complex conflict resolution, making each model suitable for different application needs like financial systems versus social media platforms.
Eventual Consistency vs. Strong Eventual Consistency ... - Baeldung - Unlike eventual consistency, strong consistency ensures all nodes see the same data without temporary inconsistencies, benefiting applications requiring real-time accuracy such as financial systems, but at the cost of performance and scalability due to the need for coordination; eventual consistency trades immediate accuracy for higher availability and scalability.
FAQs
What is data consistency?
Data consistency ensures that data remains accurate, reliable, and uniform across all databases or storage systems after any operation or transaction.
What is strong consistency?
Strong consistency ensures that every read operation returns the most recent write, maintaining a single, up-to-date view of data across all nodes in a distributed system.
What is eventual consistency?
Eventual consistency is a distributed system model guaranteeing that, given no new updates, all replicas will converge to the same data value over time.
How does strong consistency differ from eventual consistency?
Strong consistency ensures immediate data uniformity across all nodes after a write, while eventual consistency allows temporary data divergence, guaranteeing synchronization only after some time.
What are the benefits of strong consistency?
Strong consistency ensures immediate data accuracy across all nodes, eliminates stale reads, guarantees linearizability, simplifies application logic, and enhances data reliability in distributed systems.
What are the advantages of eventual consistency?
Eventual consistency reduces latency, improves system availability, enhances scalability, supports partition tolerance, and enabling high write throughput in distributed databases.
When should you use strong versus eventual consistency?
Use strong consistency when applications require immediate and guaranteed data accuracy across all nodes, such as in financial transactions or inventory management; use eventual consistency for high availability and scalability in distributed systems where temporary data discrepancies are acceptable, like social media feeds or caching.