Data independence ensures that changes in database schema do not affect application programs, enhancing system flexibility and maintainability. Data redundancy refers to the unnecessary duplication of data, which can lead to inconsistency and increased storage costs. Explore more to understand how balancing data independence and data redundancy impacts database design and performance.
Main Difference
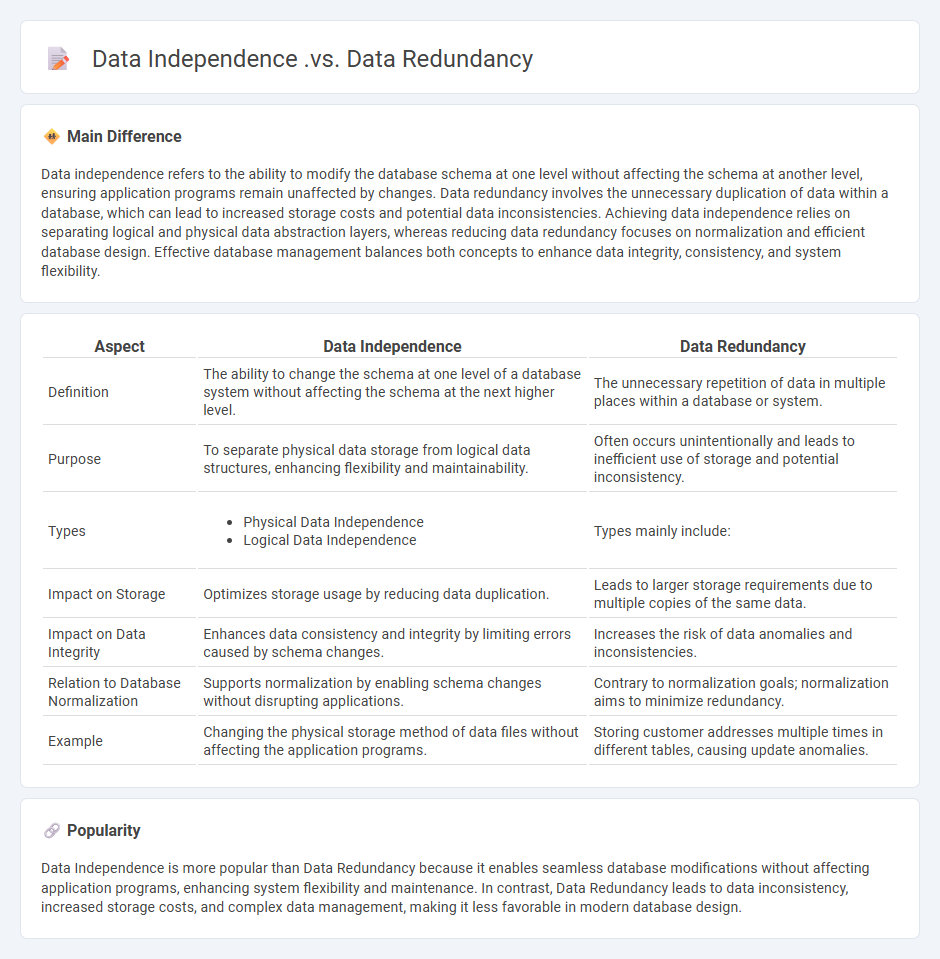
Data independence refers to the ability to modify the database schema at one level without affecting the schema at another level, ensuring application programs remain unaffected by changes. Data redundancy involves the unnecessary duplication of data within a database, which can lead to increased storage costs and potential data inconsistencies. Achieving data independence relies on separating logical and physical data abstraction layers, whereas reducing data redundancy focuses on normalization and efficient database design. Effective database management balances both concepts to enhance data integrity, consistency, and system flexibility.
Connection
Data independence reduces data redundancy by separating data storage from application programs, ensuring changes in data structure do not affect access methods. Minimizing data redundancy leads to improved data consistency and integrity across databases. Both concepts enhance database efficiency by streamlining data management and reducing unnecessary duplication.
Comparison Table
| Aspect | Data Independence | Data Redundancy |
|---|---|---|
| Definition | The ability to change the schema at one level of a database system without affecting the schema at the next higher level. | The unnecessary repetition of data in multiple places within a database or system. |
| Purpose | To separate physical data storage from logical data structures, enhancing flexibility and maintainability. | Often occurs unintentionally and leads to inefficient use of storage and potential inconsistency. |
| Types |
|
Types mainly include: |
| Impact on Storage | Optimizes storage usage by reducing data duplication. | Leads to larger storage requirements due to multiple copies of the same data. |
| Impact on Data Integrity | Enhances data consistency and integrity by limiting errors caused by schema changes. | Increases the risk of data anomalies and inconsistencies. |
| Relation to Database Normalization | Supports normalization by enabling schema changes without disrupting applications. | Contrary to normalization goals; normalization aims to minimize redundancy. |
| Example | Changing the physical storage method of data files without affecting the application programs. | Storing customer addresses multiple times in different tables, causing update anomalies. |
Logical Data Independence
Logical data independence refers to the capacity of a database management system (DBMS) to allow changes in the logical schema without altering the external schema or application programs. This property ensures that modifications in table structures, relations, or attributes do not disrupt end-user operations or require rewriting queries. It enables flexibility and scalability in database design, supporting evolving business requirements while maintaining data consistency. Most relational database systems, such as Oracle, MySQL, and SQL Server, implement mechanisms to achieve logical data independence through schema abstraction layers.
Physical Data Independence
Physical data independence allows changes in the physical storage of data without affecting the logical schema or application programs. Database management systems (DBMS) implement this principle to ensure that modifications like file organization or indexing improve performance while maintaining user interaction consistency. It facilitates system scalability and adaptability by isolating physical data structure from conceptual design. Modern relational DBMSs, such as Oracle and MySQL, provide robust mechanisms to achieve physical data independence through storage abstraction layers.
Data Duplication
Data duplication in computer systems involves creating exact copies of digital information to improve access speed, ensure data redundancy, and enhance backup processes. Techniques like file replication, database mirroring, and storage-based cloning help safeguard against data loss and system failures. Enterprises leverage data deduplication algorithms to minimize redundant data storage, optimizing disk space and boosting operational efficiency. Cloud providers such as AWS, Google Cloud, and Microsoft Azure offer built-in duplication solutions that enhance data availability and disaster recovery strategies.
Normalization
Normalization in computer science refers to the process of organizing data in databases to minimize redundancy and improve data integrity. It involves dividing large tables into smaller, related tables and defining relationships between them, typically using normal forms such as First Normal Form (1NF), Second Normal Form (2NF), and Third Normal Form (3NF). This structured approach enhances query performance and simplifies maintenance by reducing anomalies during data operations like insertion, deletion, and updating. Database management systems (DBMS) like MySQL, PostgreSQL, and Oracle widely implement normalization techniques to optimize storage and ensure consistent data representation.
Storage Efficiency
Storage efficiency in computer systems refers to the optimized use of disk space to maximize data capacity while minimizing redundancy and wastage. Techniques such as data compression, deduplication, and thin provisioning enhance storage efficiency by reducing the physical storage needed for data retention. Enterprise storage solutions from companies like Dell EMC, NetApp, and IBM integrate advanced algorithms to improve storage utilization and performance. Effective storage efficiency leads to lower operational costs and improved scalability in data centers and cloud environments.
Source and External Links
Data Independence and Redundancy - Discusses how data independence allows applications to function regardless of changes to the underlying data storage, while data redundancy refers to storing the same data in multiple locations.
Data Independence And Data Redundancy - Explains data independence as the separation of data storage and access, and data redundancy as the storage of the same data in multiple locations, which can lead to efficiency issues if not managed properly.
What is Data Redundancy? - Describes data redundancy as a practice that involves storing data in two or more places for protection and efficiency, distinguishing it broadly from data independence, which focuses on application flexibility.
FAQs
What is data independence?
Data independence is the ability to modify a database schema at one level without affecting the schema at the next higher level.
What does data redundancy mean?
Data redundancy means the unnecessary duplication of the same data within a database or storage system, leading to wasted space and potential inconsistencies.
How does data independence reduce data redundancy?
Data independence reduces data redundancy by separating data storage from application programs, allowing changes in the database schema without altering data access methods, which prevents duplicate data storage and promotes centralized data management.
Why is minimizing data redundancy important in databases?
Minimizing data redundancy in databases reduces storage costs, improves data consistency, enhances query performance, and simplifies data maintenance.
What are the types of data independence?
The types of data independence are logical data independence and physical data independence.
What are the negative effects of data redundancy?
Data redundancy causes increased storage costs, data inconsistency, higher maintenance efforts, and decreased system performance.
How do database management systems support data independence?
Database management systems support data independence by separating the physical storage of data from its logical structure through layered architecture, primarily via the physical, logical, and view levels, enabling changes in storage or schema without affecting application programs.