Fork and spawn are crucial process-creation methods in operating systems, each serving distinct purposes in concurrent execution. Fork generates a new child process duplicating the parent, sharing the same memory space initially, while spawn creates a new process independently with a separate memory space. Explore further to understand how these methods impact system performance and programming paradigms.
Main Difference
Fork creates a new process by duplicating the calling process, resulting in a child process that shares the same code and data as the parent initially, commonly used in Unix-like operating systems. Spawn launches a new process independently from the parent, typically specifying a new program to execute, often seen in Windows systems. Fork returns twice: once in the parent with the child's PID and once in the child with zero, while Spawn returns a handle to the new process. Fork is efficient for creating a process that continues similar execution flow, whereas Spawn is suited for starting entirely different applications.
Connection
Fork and spawn are both programming concepts used to create new processes or threads in operating systems. Fork duplicates the current process, creating a child process with a separate execution flow, while spawn initiates a new process, often running a different program or command. Both techniques are crucial for multitasking and parallel execution in computing environments.
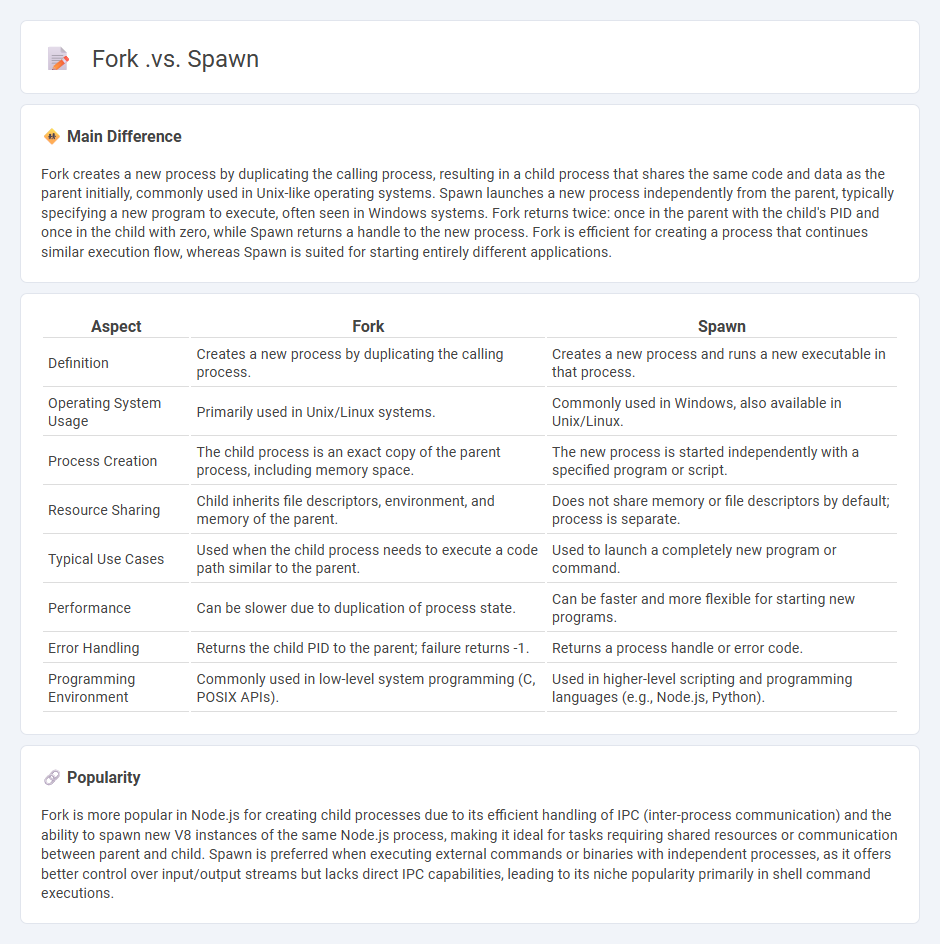
Comparison Table
| Aspect | Fork | Spawn |
|---|---|---|
| Definition | Creates a new process by duplicating the calling process. | Creates a new process and runs a new executable in that process. |
| Operating System Usage | Primarily used in Unix/Linux systems. | Commonly used in Windows, also available in Unix/Linux. |
| Process Creation | The child process is an exact copy of the parent process, including memory space. | The new process is started independently with a specified program or script. |
| Resource Sharing | Child inherits file descriptors, environment, and memory of the parent. | Does not share memory or file descriptors by default; process is separate. |
| Typical Use Cases | Used when the child process needs to execute a code path similar to the parent. | Used to launch a completely new program or command. |
| Performance | Can be slower due to duplication of process state. | Can be faster and more flexible for starting new programs. |
| Error Handling | Returns the child PID to the parent; failure returns -1. | Returns a process handle or error code. |
| Programming Environment | Commonly used in low-level system programming (C, POSIX APIs). | Used in higher-level scripting and programming languages (e.g., Node.js, Python). |
Process Creation
Process creation in computers involves initializing a new process by allocating necessary resources such as memory, CPU time, and system descriptors. The operating system typically uses system calls like fork() in Unix-based systems or CreateProcess() in Windows to generate process instances. During creation, a process control block (PCB) is established to track process state, priority, and execution context. Efficient process creation is crucial for multitasking and resource management in modern operating systems.
Parent-Child Relationship
The parent-child relationship in computer systems refers to the hierarchical connection where a parent process creates one or more child processes, establishing a control and communication link. This structure is fundamental in operating systems such as UNIX and Windows, enabling process management, resource allocation, and execution flow organization. Parent processes can monitor or terminate child processes, ensuring system stability and efficient task execution. The process tree generated by these relationships is crucial for understanding system behavior and debugging.
Resource Duplication
Resource duplication in computer systems refers to the process of creating multiple copies of data, files, or computational resources to enhance reliability, availability, and performance. Techniques such as data replication, RAID configurations, and caching optimize resource utilization and ensure fault tolerance by preventing data loss during hardware failures. Cloud environments frequently employ resource duplication for load balancing and disaster recovery, leveraging geographic distribution to minimize latency and service interruptions. Efficient resource duplication strategies reduce downtime and improve system resilience in both local and distributed computing infrastructures.
Execution Control
Execution control in computer systems manages the sequence and timing of instruction processing within the CPU, ensuring efficient and accurate program execution. It involves components like the control unit, which interprets instruction codes and generates control signals to coordinate execution stages. Advanced execution control techniques include pipelining, branch prediction, and out-of-order execution, which optimize instruction throughput and minimize latency. Effective execution control contributes to overall processor performance, energy efficiency, and system stability.
Performance Overhead
Performance overhead refers to the additional computing resources required by a system or application to execute a specific task beyond the baseline performance. This includes extra processing time, memory usage, and power consumption caused by factors such as virtualization, encryption, or debugging tools. High-performance overhead can degrade system responsiveness and increase operational costs, especially in large-scale data centers or real-time computing environments. Optimizing software algorithms and hardware architectures helps minimize overhead while maintaining functionality and security.
Source and External Links
Difference between spawn() and fork() methods in Node.js - spawn() is a general-purpose method for launching any new process and handling I/O streams, while fork() is specialized for creating new Node.js processes with built-in inter-process communication (IPC).
Fork vs Spawn in Python Multiprocessing - Forking copies the parent process's entire state and is default on Unix, whereas spawning launches a fresh Python interpreter for each child process and is default on Windows and macOS.
Understanding 'fork' and 'spawn' in Python Multiprocessing - Fork child processes inherit the parent's memory, making it fast but potentially memory-intensive, while spawn creates independent processes that must be initialized from scratch.
FAQs
What is process creation in computing?
Process creation in computing is the operation where a new process is generated by the operating system, typically through system calls like fork() or CreateProcess(), enabling multitasking and resource allocation.
What is the difference between fork and spawn?
Fork creates a new process by duplicating the current process, sharing the same code and memory space initially, while spawn starts a new process independently with its own memory and code execution environment.
How does fork work in operating systems?
The fork system call in operating systems creates a new child process by duplicating the calling parent process, resulting in two processes with identical memory images except for their process IDs.
How does spawn function in programming?
The spawn function in programming creates a new process or thread to run concurrently with the parent program, enabling parallel execution and improved resource utilization.
When should you use fork instead of spawn?
Use fork in Node.js when you need to create child processes that run separate Node.js instances with an IPC channel for communication; use spawn to execute external programs or scripts without built-in IPC.
What are the advantages of using spawn over fork?
Spawn offers better performance and lower memory usage by creating new processes without duplicating the parent process's memory space, supports streaming of I/O with child processes, and provides more fine-grained control over process execution compared to fork, which duplicates the entire parent process.
Are there security implications between fork and spawn?
Fork preserves the parent process's memory space, which can lead to inherited file descriptors and permissions, increasing security risks; spawn creates a new process with a clean environment, reducing potential security vulnerabilities.