UTF-8 and UTF-16 are encoding schemes used to represent Unicode characters, essential for global text processing and digital communication. UTF-8 encodes characters using one to four bytes, making it efficient for ASCII and widely compatible with web standards, while UTF-16 uses two or four bytes, optimizing storage for many non-Latin scripts. Explore more about how UTF-8 and UTF-16 impact software development and internationalization.
Main Difference
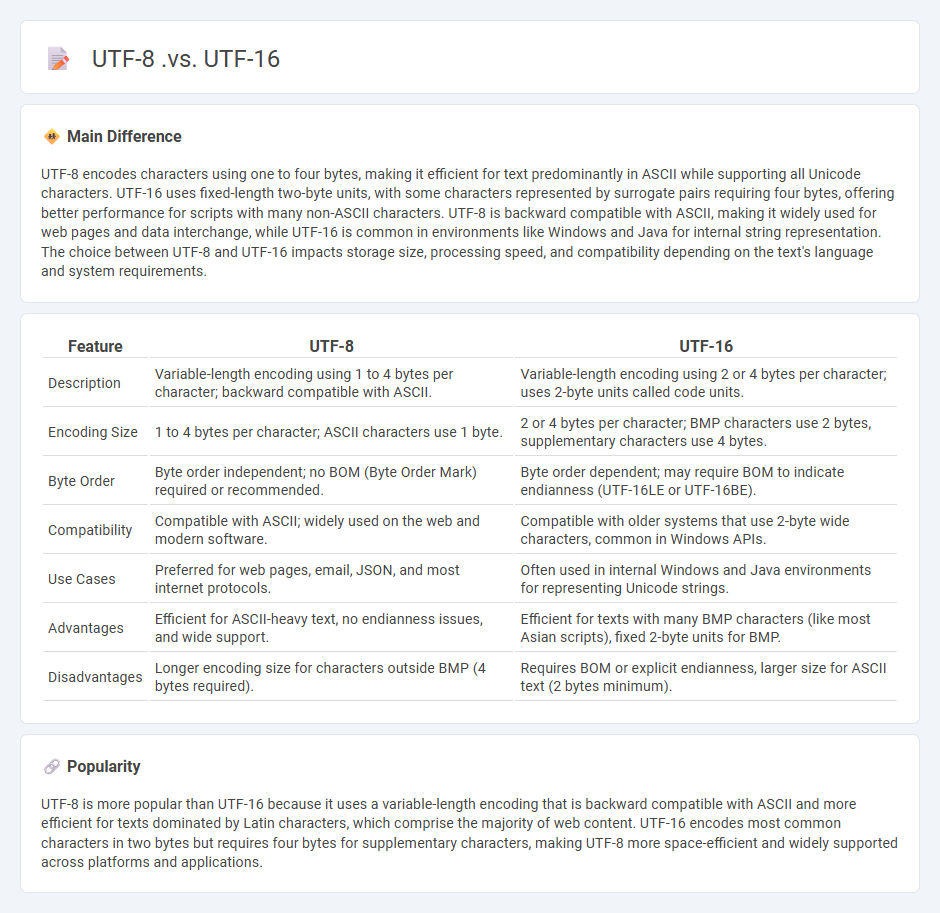
UTF-8 encodes characters using one to four bytes, making it efficient for text predominantly in ASCII while supporting all Unicode characters. UTF-16 uses fixed-length two-byte units, with some characters represented by surrogate pairs requiring four bytes, offering better performance for scripts with many non-ASCII characters. UTF-8 is backward compatible with ASCII, making it widely used for web pages and data interchange, while UTF-16 is common in environments like Windows and Java for internal string representation. The choice between UTF-8 and UTF-16 impacts storage size, processing speed, and compatibility depending on the text's language and system requirements.
Connection
UTF-8 and UTF-16 are both Unicode encoding forms designed to represent the same universal character set but differ in byte length and encoding schemes. UTF-8 uses one to four bytes per character, optimizing for ASCII compatibility and space efficiency, while UTF-16 employs one or two 16-bit code units, accommodating a broader range with variable-length encoding. Both encodings facilitate text processing across diverse systems by enabling consistent representation and interchange of Unicode characters.
Comparison Table
| Feature | UTF-8 | UTF-16 |
|---|---|---|
| Description | Variable-length encoding using 1 to 4 bytes per character; backward compatible with ASCII. | Variable-length encoding using 2 or 4 bytes per character; uses 2-byte units called code units. |
| Encoding Size | 1 to 4 bytes per character; ASCII characters use 1 byte. | 2 or 4 bytes per character; BMP characters use 2 bytes, supplementary characters use 4 bytes. |
| Byte Order | Byte order independent; no BOM (Byte Order Mark) required or recommended. | Byte order dependent; may require BOM to indicate endianness (UTF-16LE or UTF-16BE). |
| Compatibility | Compatible with ASCII; widely used on the web and modern software. | Compatible with older systems that use 2-byte wide characters, common in Windows APIs. |
| Use Cases | Preferred for web pages, email, JSON, and most internet protocols. | Often used in internal Windows and Java environments for representing Unicode strings. |
| Advantages | Efficient for ASCII-heavy text, no endianness issues, and wide support. | Efficient for texts with many BMP characters (like most Asian scripts), fixed 2-byte units for BMP. |
| Disadvantages | Longer encoding size for characters outside BMP (4 bytes required). | Requires BOM or explicit endianness, larger size for ASCII text (2 bytes minimum). |
Encoding Scheme
Encoding schemes in computer systems transform data into specific formats for efficient processing and storage. Common encoding methods include ASCII, which represents text as numerical codes, and Unicode, which supports a vast array of characters from multiple languages. Binary encoding forms the basis of machine-level data representation, using bits to encode instructions and values. Error-detecting and error-correcting codes, such as Hamming and Reed-Solomon, enhance data reliability in digital communication and storage.
Byte Storage
Byte storage in computers refers to the fundamental unit of data storage, typically consisting of 8 bits. Each byte can represent 256 distinct values, enabling the encoding of characters, numbers, and other data types. Modern computer systems utilize byte-addressable memory architectures, allowing efficient access and manipulation of data at the byte level. High-capacity storage devices, such as solid-state drives (SSDs) and hard disk drives (HDDs), are measured in gigabytes (GB) and terabytes (TB), reflecting the volume of bytes they can store.
Compatibility
Compatibility in computers refers to the ability of hardware or software components to operate together effectively without conflicts. It includes binary compatibility, ensuring software runs on a specific CPU architecture like x86 or ARM, and file format compatibility, allowing different programs to read and write the same data types such as .docx or .mp4. Hardware compatibility covers components like GPUs, CPUs, and peripherals working within the system's specifications, such as motherboard chipset support for PCIe versions or USB standards. Software compatibility often requires matching operating systems, like Windows 10 supporting DirectX 12 applications, to avoid performance issues or failures.
Performance
Computer performance refers to the efficiency and speed at which a computer system completes tasks, often measured by CPU clock speed, RAM capacity, and storage type. Modern processors like Intel Core i9 or AMD Ryzen 9 deliver multi-core processing power essential for demanding applications such as gaming and data analysis. Solid-state drives (SSD) significantly enhance data read/write speeds compared to traditional hard disk drives (HDD), improving overall system responsiveness. Benchmark scores from platforms like PassMark and Cinebench provide standardized metrics to evaluate and compare computer performance objectively.
Use Cases
Computers serve as essential tools across various industries, enabling data processing, software development, and digital communication. In healthcare, computers facilitate electronic medical records management, diagnostic imaging, and telemedicine services. The finance sector relies on computers for algorithmic trading, fraud detection, and secure transaction processing. Educational institutions utilize computers for e-learning platforms, virtual classrooms, and academic research analysis.
Source and External Links
Difference Between UTF-8 and UTF-16 - This webpage provides a detailed comparison of UTF-8 and UTF-16, highlighting their differences in byte order, character representation, and usage.
What is UTF-8 Encoding? - This guide explains the basics of UTF-8 and UTF-16, outlining how they encode Unicode characters into binary strings and their compatibility differences.
UTF-8 vs UTF-16 - A Comprehensive Comparison - This article compares UTF-8 and UTF-16, discussing their use cases and strengths, with UTF-8 being ideal for web applications and UTF-16 for scenarios requiring complex character sets.
FAQs
What is Unicode?
Unicode is a universal character encoding standard that assigns unique code points to over 143,000 characters from 154 modern and historic scripts, enabling consistent text representation across different platforms and devices.
What is the difference between UTF-8 and UTF-16?
UTF-8 encodes characters using 1 to 4 bytes and is backward compatible with ASCII, optimizing storage for English text, while UTF-16 uses 2 or 4 bytes per character, efficiently encoding most common characters but requiring more space for ASCII.
How does UTF-8 encoding work?
UTF-8 encoding represents each Unicode character using one to four bytes, where the first byte indicates the number of bytes in the sequence and continuation bytes start with the bits '10'.
How does UTF-16 encoding work?
UTF-16 encodes Unicode characters using one or two 16-bit code units; characters from the Basic Multilingual Plane use a single 16-bit unit, while supplementary characters are represented by a surrogate pair consisting of two 16-bit units.
Which is more space-efficient, UTF-8 or UTF-16?
UTF-8 is generally more space-efficient for texts dominated by ASCII characters, as it uses 1 byte per ASCII character, while UTF-16 uses at least 2 bytes; for texts with many non-ASCII characters, UTF-16 can be more space-efficient.
What characters can UTF-8 and UTF-16 represent?
UTF-8 and UTF-16 can represent all Unicode characters, encompassing over 1.1 million code points from the Basic Multilingual Plane (BMP) and supplementary planes, including scripts, symbols, emojis, and control characters.
When should you use UTF-8 or UTF-16?
Use UTF-8 for web content, ASCII compatibility, and storage efficiency with predominantly English text; use UTF-16 for applications requiring extensive use of non-Latin scripts like Chinese, Japanese, or Korean due to its fixed two-byte unit for most common characters.