Pipelining enhances processor performance by overlapping instruction stages, allowing multiple instructions to be processed simultaneously in a streamlined sequence. Superscalar architecture further improves throughput by executing multiple instructions per clock cycle using multiple execution units. Explore the differences between pipelining and superscalar techniques to understand their impact on CPU efficiency and speed.
Main Difference
Pipelining improves CPU performance by dividing instruction execution into separate stages, allowing multiple instructions to overlap in different phases, which increases instruction throughput. Superscalar architecture enhances performance by enabling multiple instructions to be issued and executed simultaneously in parallel pipelines during a single clock cycle. While pipelining focuses on instruction-level parallelism by breaking down tasks into sequential stages, superscalar takes advantage of hardware resources to execute more than one instruction concurrently. The combination of pipelining and superscalar techniques typically results in higher instruction per cycle (IPC) rates and improved processing speed.
Connection
Pipelining and superscalar architectures both enhance CPU performance by increasing instruction throughput through parallelism in instruction execution. Pipelining divides instruction processing into multiple stages, allowing overlapping execution, while superscalar designs issue multiple instructions simultaneously in a single clock cycle using multiple execution units. Combining these techniques enables modern processors to execute several instructions per cycle more efficiently, significantly boosting computational speed.
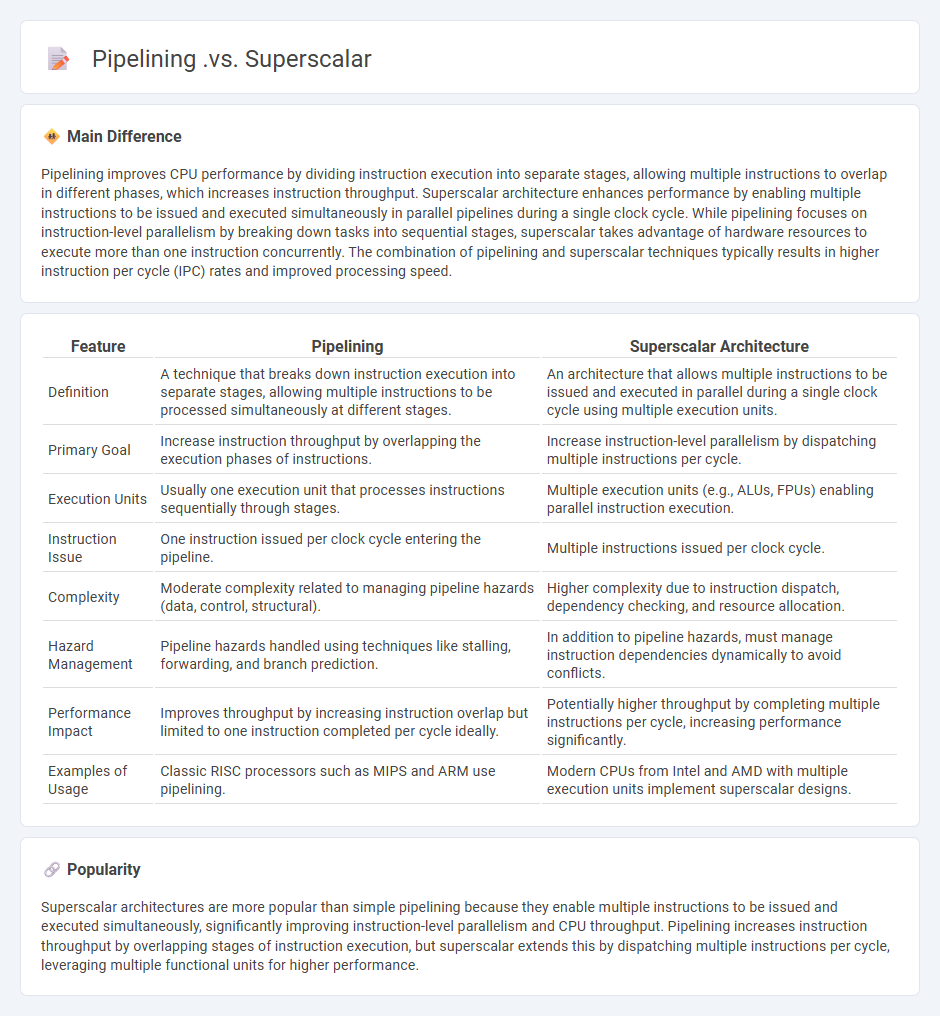
Comparison Table
| Feature | Pipelining | Superscalar Architecture |
|---|---|---|
| Definition | A technique that breaks down instruction execution into separate stages, allowing multiple instructions to be processed simultaneously at different stages. | An architecture that allows multiple instructions to be issued and executed in parallel during a single clock cycle using multiple execution units. |
| Primary Goal | Increase instruction throughput by overlapping the execution phases of instructions. | Increase instruction-level parallelism by dispatching multiple instructions per cycle. |
| Execution Units | Usually one execution unit that processes instructions sequentially through stages. | Multiple execution units (e.g., ALUs, FPUs) enabling parallel instruction execution. |
| Instruction Issue | One instruction issued per clock cycle entering the pipeline. | Multiple instructions issued per clock cycle. |
| Complexity | Moderate complexity related to managing pipeline hazards (data, control, structural). | Higher complexity due to instruction dispatch, dependency checking, and resource allocation. |
| Hazard Management | Pipeline hazards handled using techniques like stalling, forwarding, and branch prediction. | In addition to pipeline hazards, must manage instruction dependencies dynamically to avoid conflicts. |
| Performance Impact | Improves throughput by increasing instruction overlap but limited to one instruction completed per cycle ideally. | Potentially higher throughput by completing multiple instructions per cycle, increasing performance significantly. |
| Examples of Usage | Classic RISC processors such as MIPS and ARM use pipelining. | Modern CPUs from Intel and AMD with multiple execution units implement superscalar designs. |
Instruction-level parallelism (ILP)
Instruction-level parallelism (ILP) in computer architecture refers to the ability of a processor to execute multiple instructions simultaneously by overlapping their execution within a single CPU cycle. Modern superscalar processors exploit ILP by dynamically scheduling instructions through techniques such as out-of-order execution, speculative execution, and multiple functional units. Hardware mechanisms like branch prediction and register renaming further enhance ILP by minimizing pipeline stalls and data hazards. Achieving high ILP significantly improves CPU throughput and overall system performance in applications ranging from scientific computing to real-time data processing.
Pipeline stages
Pipeline stages in computer architecture refer to the sequential steps through which an instruction passes during its execution. Common stages include Instruction Fetch (IF), Instruction Decode (ID), Execute (EX), Memory Access (MEM), and Write Back (WB). These stages enable overlapping execution of multiple instructions, improving CPU throughput and overall performance. Modern processors often implement deeper pipelines with additional stages to enhance clock speed and efficiency.
Throughput
Throughput in computer systems measures the rate at which data is successfully processed or transmitted within a given time frame, typically expressed in bits per second (bps) or instructions per second (IPS). It is a critical performance metric in network engineering, computer architecture, and data storage, influencing overall system efficiency and user experience. High throughput ensures faster data transfer rates and optimal resource utilization, directly impacting applications like cloud computing, streaming, and big data analytics. Monitoring throughput helps identify bottlenecks and optimize hardware or software configurations to meet specific performance requirements.
Multiple instruction issue
Computer systems encounter multiple instruction issues when simultaneous commands cause conflicts or resource contention, leading to performance bottlenecks. Modern CPUs use techniques such as out-of-order execution and instruction pipelining to alleviate these problems by processing instructions more efficiently. Multi-core processors distribute workloads across cores, minimizing instruction clashes and maximizing throughput. Advanced compilers optimize code to reduce dependency and improve instruction-level parallelism.
Hazard management
Hazard management in computer architecture focuses on identifying and resolving conflicts that occur during instruction execution in pipelined processors. Data hazards arise when instructions depend on the results of prior instructions still in the pipeline, requiring techniques such as forwarding, stalling, or hazard detection units to prevent incorrect operation. Control hazards occur from branch instructions, leading to pipeline flushing or branch prediction strategies to maintain flow efficiency. Effective hazard management enhances processor throughput and minimizes pipeline stalls, critical for high-performance computing systems.
Source and External Links
## PipeliningPipelining - Pipelining is a technique that divides the execution of instructions into stages, allowing multiple instructions to be processed simultaneously across different stages, but each stage handles only one instruction at a time.
## SuperscalarSuperscalar Processor - A superscalar processor executes multiple instructions in parallel by issuing them to different execution units within a single processor, thus increasing throughput beyond one instruction per clock cycle.
## Superscalar vs. SuperpipeliningSuperscalar vs. Superpipelined Machines - Superscalar machines execute multiple instructions per cycle, while superpipelined machines execute one instruction per cycle but with shorter cycle times, enhancing performance through faster execution.
FAQs
What is pipelining in CPU architecture?
Pipelining in CPU architecture is a technique that divides instruction processing into separate stages, allowing multiple instructions to overlap in execution, thereby increasing the CPU's instruction throughput and efficiency.
What is superscalar execution?
Superscalar execution is a CPU architecture technique that enables multiple instructions to be issued and executed simultaneously within a single clock cycle, enhancing instruction-level parallelism and overall processing performance.
How does pipelining improve performance?
Pipelining improves performance by allowing multiple instruction stages to overlap execution, increasing instruction throughput and reducing overall CPU cycle time.
How do superscalar processors differ from pipelined processors?
Superscalar processors execute multiple instructions per clock cycle using multiple functional units, while pipelined processors improve instruction throughput by dividing execution into sequential stages but typically execute one instruction per stage at a time.
What are the main stages of a pipeline?
The main stages of a pipeline are fetch, decode, execute, memory access, and write-back.
What are the limitations of pipelining versus superscalar?
Pipelining is limited by hazards such as data, control, and structural hazards that cause stalls and reduce instruction throughput, while superscalar architectures face complexity in instruction scheduling, dependency checking, and hardware resource allocation but can issue multiple instructions per cycle for higher parallelism.
Can a processor be both pipelined and superscalar?
Yes, a processor can be both pipelined and superscalar by implementing multiple instruction pipelines that allow simultaneous execution of multiple instructions per clock cycle.