Corpus linguistics utilizes large collections of real-world text data to analyze language patterns and structures empirically. Computational linguistics integrates computer science and linguistic theory to develop algorithms for natural language processing and automated language understanding. Explore deeper insights into their methodologies and applications to enhance your linguistic expertise.
Main Difference
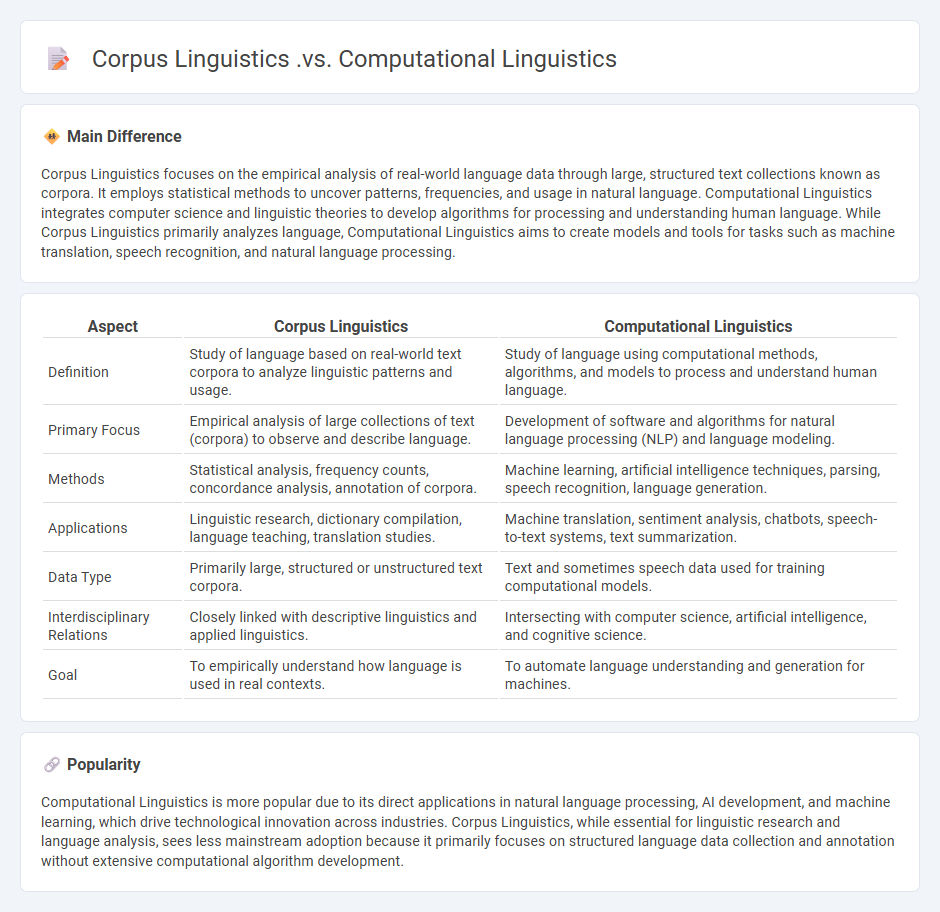
Corpus Linguistics focuses on the empirical analysis of real-world language data through large, structured text collections known as corpora. It employs statistical methods to uncover patterns, frequencies, and usage in natural language. Computational Linguistics integrates computer science and linguistic theories to develop algorithms for processing and understanding human language. While Corpus Linguistics primarily analyzes language, Computational Linguistics aims to create models and tools for tasks such as machine translation, speech recognition, and natural language processing.
Connection
Corpus Linguistics provides large, structured datasets of authentic language use that Computational Linguistics leverages for developing and training natural language processing (NLP) models. Computational Linguistics applies algorithms and machine learning techniques to analyze corpora, enabling advancements in machine translation, speech recognition, and text mining. The synergy between these fields enhances linguistic research, improving accuracy and efficiency in language technology applications.
Comparison Table
| Aspect | Corpus Linguistics | Computational Linguistics |
|---|---|---|
| Definition | Study of language based on real-world text corpora to analyze linguistic patterns and usage. | Study of language using computational methods, algorithms, and models to process and understand human language. |
| Primary Focus | Empirical analysis of large collections of text (corpora) to observe and describe language. | Development of software and algorithms for natural language processing (NLP) and language modeling. |
| Methods | Statistical analysis, frequency counts, concordance analysis, annotation of corpora. | Machine learning, artificial intelligence techniques, parsing, speech recognition, language generation. |
| Applications | Linguistic research, dictionary compilation, language teaching, translation studies. | Machine translation, sentiment analysis, chatbots, speech-to-text systems, text summarization. |
| Data Type | Primarily large, structured or unstructured text corpora. | Text and sometimes speech data used for training computational models. |
| Interdisciplinary Relations | Closely linked with descriptive linguistics and applied linguistics. | Intersecting with computer science, artificial intelligence, and cognitive science. |
| Goal | To empirically understand how language is used in real contexts. | To automate language understanding and generation for machines. |
Annotation
Annotation involves adding explanatory notes or comments to a text, image, or data set to enhance understanding, provide context, or highlight key information. It is widely used in educational settings, research, and digital humanities to facilitate deeper analysis and interpretation of content. In machine learning, annotation is crucial for labeling datasets, enabling algorithms to recognize patterns and improve accuracy. Effective annotation requires clear, concise, and relevant input to maximize the utility of the annotated material.
Quantitative Analysis
Quantitative analysis involves the systematic empirical investigation of measurable data through statistical, mathematical, or computational techniques to understand patterns, relationships, and trends. This method is extensively applied in finance, economics, marketing, and social sciences to provide objective insights and support data-driven decision-making. Tools such as regression analysis, time-series forecasting, and hypothesis testing are commonly used to interpret complex datasets and validate theoretical models. Modern quantitative analysis leverages big data and machine learning algorithms to enhance predictive accuracy and operational efficiency.
Natural Language Processing (NLP)
Natural Language Processing (NLP) leverages algorithms to analyze, understand, and generate human language, enabling applications such as machine translation, sentiment analysis, and chatbots. Recent advancements in deep learning, particularly transformer models like GPT-4 and BERT, have significantly enhanced NLP accuracy and contextual understanding. NLP techniques process vast datasets from diverse sources including texts, social media, and speech to extract meaningful insights. Industries such as healthcare, finance, and customer service increasingly rely on NLP for automation and data-driven decision-making.
Data-driven Methods
Data-driven methods utilize extensive datasets and advanced algorithms to uncover patterns and inform decision-making across various industries. Machine learning models, such as supervised and unsupervised learning, optimize predictive accuracy by training on large volumes of structured and unstructured data. These techniques enable real-time analytics, enhancing operational efficiency and customer insights in sectors like finance, healthcare, and marketing. Emphasizing continuous data integration and quality ensures scalable and adaptable solutions for dynamic business environments.
Theoretical Linguistics
Theoretical linguistics focuses on the underlying structures of language, analyzing syntax, phonology, morphology, and semantics to uncover universal principles. It examines the mental representations and cognitive processes that enable language acquisition and use. Key frameworks include generative grammar developed by Noam Chomsky, which emphasizes innate linguistic knowledge. Research in this field informs computational linguistics, language teaching, and psycholinguistics by modeling how language operates in the human mind.
Source and External Links
Unlocking Language Patterns - Corpus linguistics is the study of language using large text databases (corpora) to identify patterns and usage, while computational linguistics focuses on developing algorithms and models for machines to process and understand human language, often using data from corpora.
Theory-driven and Corpus-driven Computational Linguistics - Both fields use electronic corpora, but corpus linguistics is more about analyzing language data directly for patterns, whereas computational linguistics emphasizes formal modeling and automating the understanding and generation of language by computers.
Linguistic Corpora - Corpus linguistics uses corpora as a basis for linguistic description and hypothesis testing, while computational linguistics often builds on these corpora to develop applications like speech recognition and machine translation.
FAQs
What is corpus linguistics?
Corpus linguistics is the study of language based on large, structured collections of real-world text called corpora, analyzing patterns and usage through computational methods.
What is computational linguistics?
Computational linguistics is the interdisciplinary study of using computer algorithms and models to analyze, process, and generate natural language.
How do corpus linguistics and computational linguistics differ?
Corpus linguistics analyzes language through large text collections to study actual language use, while computational linguistics develops algorithms and models to process and understand human language automatically.
What kind of data do corpus linguists use?
Corpus linguists use large, structured collections of real-world text or spoken language data called corpora to analyze language patterns, frequency, and usage.
What are the main goals of computational linguistics?
Computational linguistics aims to develop algorithms for natural language understanding, enable human-computer interaction through natural language, automate language translation, enhance speech recognition and synthesis, and facilitate linguistic data analysis.
How does technology impact corpus linguistics?
Technology enhances corpus linguistics by enabling large-scale data storage, efficient text processing, advanced annotation tools, and sophisticated statistical analysis for language research.
Can computational linguistics work without corpora?
Computational linguistics fundamentally relies on corpora for training, evaluation, and modeling language patterns, making corpora essential for its effective functioning.