Interrater reliability measures the consistency of assessments across different evaluators, ensuring uniformity in observations or ratings. Intrarater reliability evaluates the stability of measurements taken by the same individual over time, highlighting personal consistency in data collection. Explore detailed distinctions and applications to enhance assessment accuracy in your research.
Main Difference
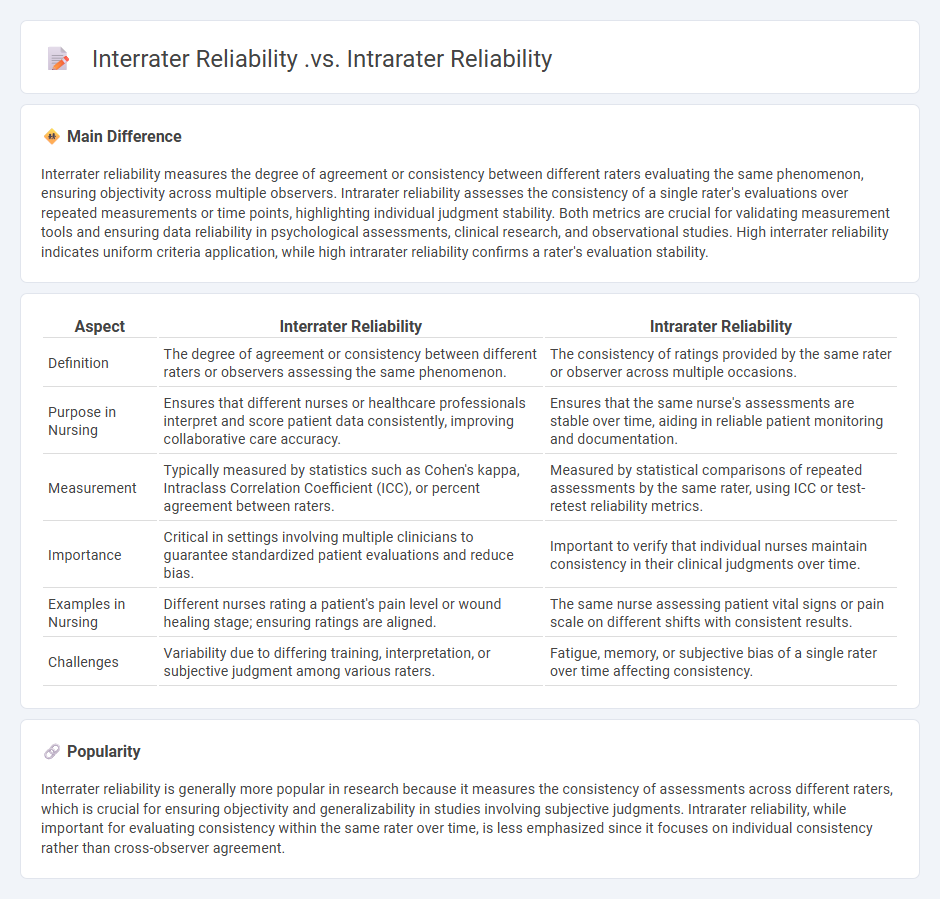
Interrater reliability measures the degree of agreement or consistency between different raters evaluating the same phenomenon, ensuring objectivity across multiple observers. Intrarater reliability assesses the consistency of a single rater's evaluations over repeated measurements or time points, highlighting individual judgment stability. Both metrics are crucial for validating measurement tools and ensuring data reliability in psychological assessments, clinical research, and observational studies. High interrater reliability indicates uniform criteria application, while high intrarater reliability confirms a rater's evaluation stability.
Connection
Interrater reliability and intrarater reliability both measure the consistency of assessments, with interrater reliability focusing on agreement between different raters, while intrarater reliability evaluates the stability of assessments by the same rater over time. High intrarater reliability often supports higher interrater reliability by ensuring each rater consistently applies the same criteria. These reliability metrics are essential in fields like psychology, medicine, and behavioral sciences to validate measurement tools and ensure data quality.
Comparison Table
| Aspect | Interrater Reliability | Intrarater Reliability |
|---|---|---|
| Definition | The degree of agreement or consistency between different raters or observers assessing the same phenomenon. | The consistency of ratings provided by the same rater or observer across multiple occasions. |
| Purpose in Nursing | Ensures that different nurses or healthcare professionals interpret and score patient data consistently, improving collaborative care accuracy. | Ensures that the same nurse's assessments are stable over time, aiding in reliable patient monitoring and documentation. |
| Measurement | Typically measured by statistics such as Cohen's kappa, Intraclass Correlation Coefficient (ICC), or percent agreement between raters. | Measured by statistical comparisons of repeated assessments by the same rater, using ICC or test-retest reliability metrics. |
| Importance | Critical in settings involving multiple clinicians to guarantee standardized patient evaluations and reduce bias. | Important to verify that individual nurses maintain consistency in their clinical judgments over time. |
| Examples in Nursing | Different nurses rating a patient's pain level or wound healing stage; ensuring ratings are aligned. | The same nurse assessing patient vital signs or pain scale on different shifts with consistent results. |
| Challenges | Variability due to differing training, interpretation, or subjective judgment among various raters. | Fatigue, memory, or subjective bias of a single rater over time affecting consistency. |
Consistency
Consistency in nursing ensures reliable patient care by following established protocols and evidence-based practices. Maintaining consistent communication between healthcare team members reduces errors and enhances patient safety. Consistent documentation in electronic health records supports accurate monitoring of patient progress and treatment outcomes. Emphasizing consistency in nursing practice improves overall healthcare quality and patient satisfaction.
Multiple Raters
Multiple raters in nursing enhance the reliability and validity of patient assessments by providing diverse perspectives and minimizing individual bias. This method is particularly vital in clinical evaluations, where consistent scoring across different healthcare professionals improves diagnostic accuracy and treatment planning. Incorporating multiple nursing raters supports evidence-based practice by ensuring comprehensive data collection and robust inter-rater agreement metrics. Studies demonstrate that using standardized tools with multiple raters significantly increases the quality of patient outcome measurements in various nursing specialties.
Single Rater
Single rater reliability in nursing research assesses the consistency of a single evaluator's measurements or observations over time, crucial for ensuring accurate patient assessments and clinical data. This method reduces variability related to multiple raters, enhancing the precision of tools like pain scales or depression inventories used in nursing practice. Studies show that single rater reliability coefficients often exceed 0.80, indicating strong internal consistency and reliability in nursing assessments. Reliable single rater evaluations support evidence-based nursing decisions and improve patient care outcomes.
Agreement
In nursing, an agreement often refers to formal contracts or mutual understandings between healthcare providers and patients to ensure clear communication and consent for treatment plans. These agreements facilitate patient safety, adherence to ethical standards, and legal compliance within healthcare settings. Nursing agreements also include collaborations between institutions and staff to optimize patient care and professional responsibilities. Detailed documentation of these agreements supports accountability and quality improvement in clinical practice.
Measurement Accuracy
Measurement accuracy in nursing is critical for ensuring reliable patient assessments and effective care planning. Precise measurement of vital signs such as blood pressure, temperature, and respiratory rate directly impacts clinical decision-making and patient outcomes. Utilizing calibrated medical devices and standardized protocols reduces errors and enhances data validity. Accurate data collection supports early detection of health complications, improving overall patient safety and treatment efficacy.
Source and External Links
Inter-Rater and Intra-Rater Reliability Evaluation - This article discusses the importance of inter-rater and intra-rater reliability in evaluating the consistency of data recorded by raters in various settings.
Inter-Rater and Intra-Rater Reliability: Facets Help - The webpage provides an overview of inter-rater and intra-rater reliability, including how they are measured using different statistical methods.
Inter-Rater Reliability in Psychology - This lesson explains the concept of inter-rater reliability and how it differs from intra-rater reliability, highlighting methods like Cohen's Kappa and Spearman's Rho for calculation.
FAQs
What is reliability in measurement?
Reliability in measurement refers to the consistency and stability of a measurement instrument or procedure, indicating its ability to produce the same results under consistent conditions.
What is interrater reliability?
Interrater reliability measures the consistency of ratings or assessments provided by multiple observers evaluating the same phenomenon.
What is intrarater reliability?
Intrarater reliability measures the consistency of a single rater's assessments or measurements across multiple trials over time.
How does interrater reliability differ from intrarater reliability?
Interrater reliability measures the consistency of ratings between different observers, while intrarater reliability assesses the consistency of ratings made by the same observer across multiple occasions.
Why is interrater reliability important in research?
Interrater reliability ensures consistency and objectivity in data collection by measuring the degree of agreement among different raters, enhancing the validity and reproducibility of research findings.
What factors affect intrarater reliability?
Intrarater reliability is affected by factors such as tester consistency, measurement tools accuracy, environmental conditions, subject variability, and time intervals between assessments.
How are reliability statistics calculated?
Reliability statistics are calculated using methods like Cronbach's alpha, test-retest correlation, split-half reliability, or inter-rater reliability, which measure internal consistency, stability over time, consistency between halves of a test, or agreement among raters respectively.