B-tree and B+ tree are advanced data structures commonly used in database indexing and file systems to optimize search, insertion, and deletion operations. B-tree stores keys and data in all nodes, while B+ tree maintains data only in leaf nodes, enabling faster range queries through linked leaf nodes. Explore detailed comparisons and use cases to understand which structure best fits your application needs.
Main Difference
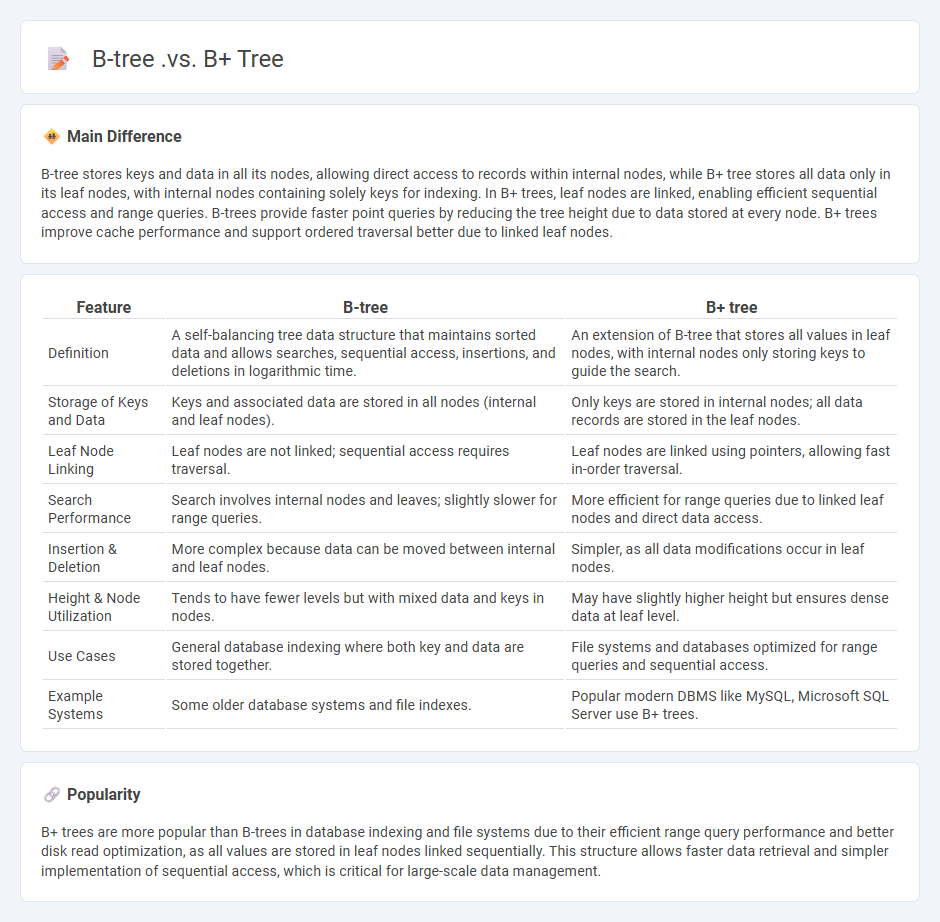
B-tree stores keys and data in all its nodes, allowing direct access to records within internal nodes, while B+ tree stores all data only in its leaf nodes, with internal nodes containing solely keys for indexing. In B+ trees, leaf nodes are linked, enabling efficient sequential access and range queries. B-trees provide faster point queries by reducing the tree height due to data stored at every node. B+ trees improve cache performance and support ordered traversal better due to linked leaf nodes.
Connection
B-tree and B+ tree are connected as balanced tree data structures used to maintain sorted data and allow efficient insertion, deletion, and search operations in databases and file systems. Both use nodes with multiple keys and children, but B+ tree stores all values in leaf nodes linked sequentially, enabling faster range queries. The structural variation in B+ tree enhances performance in disk-based storage systems compared to the classical B-tree.
Comparison Table
| Feature | B-tree | B+ tree |
|---|---|---|
| Definition | A self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. | An extension of B-tree that stores all values in leaf nodes, with internal nodes only storing keys to guide the search. |
| Storage of Keys and Data | Keys and associated data are stored in all nodes (internal and leaf nodes). | Only keys are stored in internal nodes; all data records are stored in the leaf nodes. |
| Leaf Node Linking | Leaf nodes are not linked; sequential access requires traversal. | Leaf nodes are linked using pointers, allowing fast in-order traversal. |
| Search Performance | Search involves internal nodes and leaves; slightly slower for range queries. | More efficient for range queries due to linked leaf nodes and direct data access. |
| Insertion & Deletion | More complex because data can be moved between internal and leaf nodes. | Simpler, as all data modifications occur in leaf nodes. |
| Height & Node Utilization | Tends to have fewer levels but with mixed data and keys in nodes. | May have slightly higher height but ensures dense data at leaf level. |
| Use Cases | General database indexing where both key and data are stored together. | File systems and databases optimized for range queries and sequential access. |
| Example Systems | Some older database systems and file indexes. | Popular modern DBMS like MySQL, Microsoft SQL Server use B+ trees. |
Node Structure
A node in computer science represents a basic unit of a data structure, such as a linked list, tree, or graph. Each node typically contains data and one or more references (or pointers) to other nodes, enabling efficient data organization and traversal. Nodes facilitate complex data relationships, supporting dynamic memory allocation and flexible structures for algorithms. In binary trees, nodes have at most two child nodes, while in graphs, nodes can connect to multiple neighbors.
Data Storage
Data storage in computers involves saving digital information on various media such as hard disk drives (HDDs), solid-state drives (SSDs), and cloud storage platforms. SSDs offer faster data access speeds and increased durability compared to traditional HDDs, making them the preferred choice for modern computing devices. Cloud storage solutions like Amazon S3 and Google Cloud Storage provide scalable, remotely accessible data management options for enterprise applications. Efficient data storage ensures quick retrieval and secure preservation of critical files across consumer and business environments.
Leaf Nodes
Leaf nodes represent the terminal points in data structures such as trees and graphs, containing no child nodes beneath them. They are crucial in binary search trees, decision trees, and tries, marking the completion of a path or data entry. In computer algorithms, leaf nodes often store the final output, key, or value required for processing or retrieval. Efficient identification and handling of leaf nodes enhance the performance of search, traversal, and hierarchical data management tasks.
Search Efficiency
Search efficiency in computing refers to the optimization of algorithms and data structures to minimize the time and resources required to retrieve relevant information from large datasets. Techniques such as indexing, hashing, and binary search significantly improve performance by reducing the search space and computational complexity. Advanced methods like machine learning-driven search and heuristic-based algorithms enhance precision and speed, especially in unstructured data environments. Evaluating search efficiency involves metrics like time complexity (O(n), O(log n)), memory usage, and response latency, crucial for applications in databases, information retrieval, and artificial intelligence systems.
Use Cases
Computer use cases span diverse applications such as data processing, software development, and network management. Computers enhance productivity through automation in sectors like finance, healthcare, and education. Advanced technologies including artificial intelligence, machine learning, and cloud computing rely on powerful computer systems for efficient execution. Security implementations on computers protect sensitive information against cyber threats and unauthorized access.
Source and External Links
B Tree vs B+ Tree: Which to Use - Hypermode - B+ trees store data only in leaf nodes with internal nodes containing keys and pointers, enabling better disk storage efficiency, faster search due to reduced tree height, and linked leaf nodes support efficient sequential access such as range queries, unlike B-trees where data can be in any node.
B-Tree & B+ Tree - Blocks and Files - B-trees store data in all nodes and require traversal back up for sequential access, while B+ trees store data only in linked leaf nodes, providing more efficient range queries and better space utilization by avoiding duplicated keys in leaves compared to internal nodes.
Difference Between B Tree and B+ Tree - Shiksha - B+ trees uniquely store all actual data in linked leaf nodes, which improves range query performance and sequential access, with internal nodes holding only keys, whereas B-trees have keys and data in all nodes allowing efficient exact match but less efficient sequential access.
FAQs
What is a B-tree?
A B-tree is a self-balancing tree data structure that maintains sorted data and allows efficient insertion, deletion, and search operations in logarithmic time.
What is a B+ tree?
A B+ tree is a balanced tree data structure used in databases and file systems, characterized by all values stored at leaf nodes with internal nodes serving as indexes to guide searches efficiently.
How does a B-tree differ from a B+ tree?
A B-tree stores keys and data in both internal and leaf nodes, while a B+ tree stores keys in internal nodes but keeps all data only in the leaf nodes, which are linked for efficient range queries.
What are the advantages of using a B+ tree?
B+ trees provide efficient range queries, maintain sorted data, optimize disk reads through balanced multi-level indexing, and support fast insertion, deletion, and search operations in database and file systems.
Where are B-trees commonly used?
B-trees are commonly used in databases and file systems for efficient data indexing and retrieval.
Why might a database prefer B+ trees over B-trees?
A database prefers B+ trees over B-trees because B+ trees store all values in leaf nodes arranged sequentially, enabling efficient range queries and faster disk-based data retrieval due to improved node utilization and simplified tree traversal.
How do B-trees and B+ trees handle range queries?
B-trees handle range queries by performing a search to locate the starting key, then traversing sibling nodes via pointers in the internal nodes to retrieve subsequent keys, while B+ trees optimize range queries by storing all data keys in a linked leaf node sequence, enabling efficient sequential access without accessing internal nodes.