Data lakes store vast amounts of raw, unstructured data from diverse sources, enabling flexible analytics and machine learning applications. Data warehouses organize structured data optimized for fast querying and business intelligence reporting, supporting strategic decision-making. Explore the key differences between data lakes and data warehouses to determine which solution fits your organization's data management needs.
Main Difference
A Data Lake stores vast amounts of raw, unstructured, and semi-structured data from diverse sources, enabling flexible analytics and machine learning applications. In contrast, a Data Warehouse organizes structured, processed data optimized for fast query performance and business intelligence reporting. Data Lakes use technologies like Hadoop and support schema-on-read, while Data Warehouses rely on relational databases with schema-on-write. Storage costs for Data Lakes are typically lower due to cheaper commodity hardware and cloud storage options.
Connection
Data lakes and data warehouses are connected through their complementary roles in data management; data lakes store vast amounts of raw, unstructured data ideal for big data analytics and machine learning, while data warehouses hold structured, processed data optimized for business intelligence and reporting. Data pipelines and ETL (Extract, Transform, Load) processes facilitate the transfer and transformation of data from lakes to warehouses, ensuring data quality and schema adherence. Integrating these systems enables organizations to leverage both detailed raw data and curated datasets to drive comprehensive analytics and strategic decision-making.
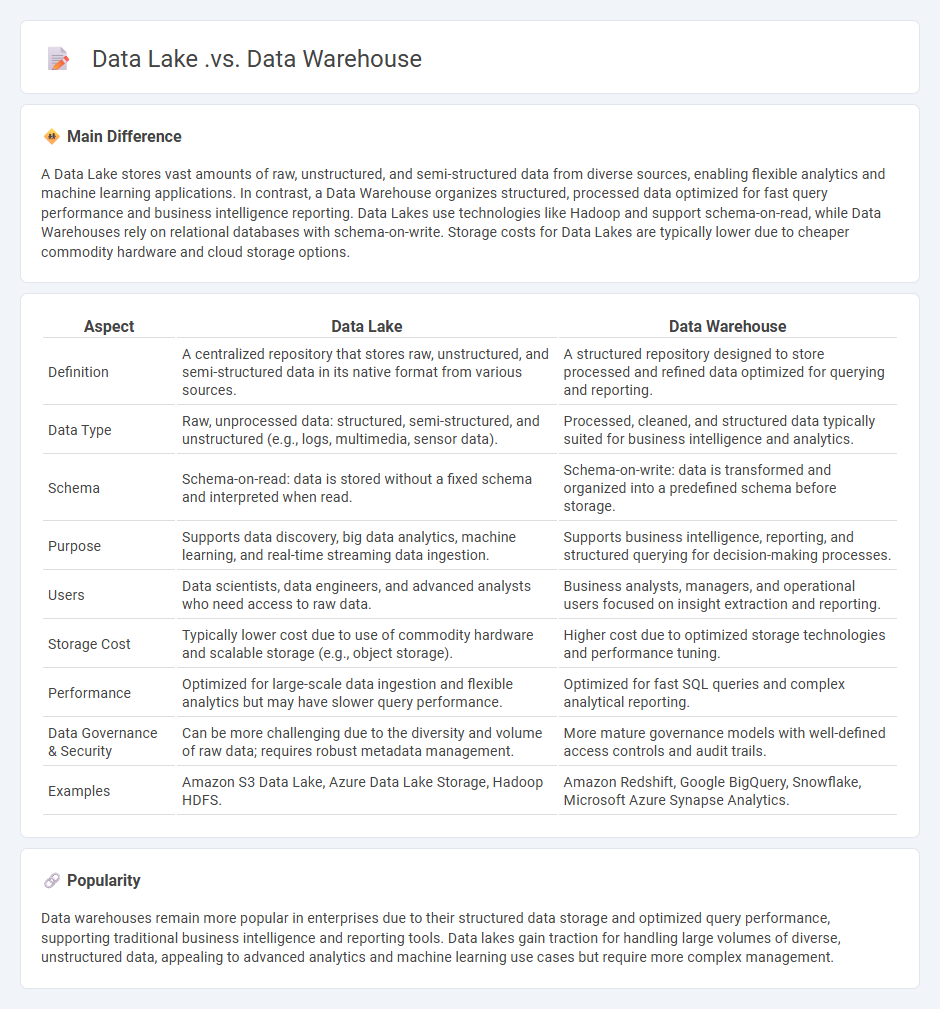
Comparison Table
| Aspect | Data Lake | Data Warehouse |
|---|---|---|
| Definition | A centralized repository that stores raw, unstructured, and semi-structured data in its native format from various sources. | A structured repository designed to store processed and refined data optimized for querying and reporting. |
| Data Type | Raw, unprocessed data: structured, semi-structured, and unstructured (e.g., logs, multimedia, sensor data). | Processed, cleaned, and structured data typically suited for business intelligence and analytics. |
| Schema | Schema-on-read: data is stored without a fixed schema and interpreted when read. | Schema-on-write: data is transformed and organized into a predefined schema before storage. |
| Purpose | Supports data discovery, big data analytics, machine learning, and real-time streaming data ingestion. | Supports business intelligence, reporting, and structured querying for decision-making processes. |
| Users | Data scientists, data engineers, and advanced analysts who need access to raw data. | Business analysts, managers, and operational users focused on insight extraction and reporting. |
| Storage Cost | Typically lower cost due to use of commodity hardware and scalable storage (e.g., object storage). | Higher cost due to optimized storage technologies and performance tuning. |
| Performance | Optimized for large-scale data ingestion and flexible analytics but may have slower query performance. | Optimized for fast SQL queries and complex analytical reporting. |
| Data Governance & Security | Can be more challenging due to the diversity and volume of raw data; requires robust metadata management. | More mature governance models with well-defined access controls and audit trails. |
| Examples | Amazon S3 Data Lake, Azure Data Lake Storage, Hadoop HDFS. | Amazon Redshift, Google BigQuery, Snowflake, Microsoft Azure Synapse Analytics. |
Structured vs Unstructured Data
Structured data in computer systems refers to organized information stored in fixed fields within databases, such as SQL tables, enabling efficient querying and analysis. Unstructured data includes diverse formats like text documents, images, videos, and social media content, lacking a predefined data model or schema. Technologies like NoSQL databases and big data analytics platforms are specifically designed to manage and interpret unstructured data. Machine learning and natural language processing techniques are increasingly employed to extract meaningful insights from unstructured datasets.
Schema-on-Read vs Schema-on-Write
Schema-on-Read and Schema-on-Write are two contrasting data management approaches in computer systems. Schema-on-Write enforces a predefined schema before data is stored, ensuring data consistency and optimized query performance, commonly used in traditional relational databases like MySQL and Oracle. Schema-on-Read allows data to be stored in its raw form, applying the schema only during data retrieval, which provides flexibility and scalability, especially in big data environments such as Hadoop and Amazon S3. Choosing between these methods depends on factors like data volume, query complexity, and the need for real-time analytics or data transformation.
Scalability and Storage
Scalability in computer systems refers to the ability to handle increasing workloads or expand resources efficiently without performance degradation. Storage scalability involves expanding data capacity through scalable storage solutions like cloud storage, network-attached storage (NAS), or storage area networks (SAN). Modern systems achieve scalability with distributed computing architectures, enabling seamless integration of additional servers and storage nodes. Key technologies supporting scalable storage include solid-state drives (SSDs), high-throughput interfaces like NVMe, and data replication for redundancy.
Real-Time Analytics vs Historical Analysis
Real-time analytics processes data instantaneously to provide immediate insights crucial for time-sensitive decision-making in computing environments. Historical analysis examines past datasets to identify trends, patterns, and anomalies, supporting strategic planning and predictive modeling. Real-time systems leverage streaming data technologies such as Apache Kafka and Apache Flink, while historical analysis relies on data warehouses and big data platforms like Hadoop and Spark. Both approaches complement each other, enabling comprehensive data-driven strategies in computer science and IT operations.
ETL (Extract, Transform, Load)
ETL (Extract, Transform, Load) is a critical data integration process in computer systems that involves extracting data from multiple sources, transforming it into a suitable format, and loading it into a target database or data warehouse. Widely used in Business Intelligence, ETL frameworks enable efficient data consolidation, cleansing, and analysis across platforms such as SQL Server, Oracle, and cloud services like AWS Redshift. Key tools in ETL workflows include Apache NiFi, Talend, Informatica PowerCenter, and Microsoft SSIS, which provide automation and scalability for large-scale data operations. ETL ensures data quality and consistency, optimizing decision-making and reporting in enterprise environments.
Source and External Links
Difference between Data Lake and Data Warehouse - This article highlights the key differences between data lakes, which store raw data without schema requirements, and data warehouses, which store structured data for business insights.
Data Lake vs Data Warehouse vs Data Mart - This comparison discusses the differences in data storage, preprocessing, and use cases between data lakes, data warehouses, and data marts.
Data Lake vs. Data Warehouse: Definitions, Key Differences - This blog post explains how data lakes store raw, unstructured data, while data warehouses store refined, structured data with predefined schemas for better query performance.
FAQs
What is a data lake?
A data lake is a centralized repository that stores vast amounts of raw, unstructured, and structured data in its native format for advanced analytics and machine learning.
What is a data warehouse?
A data warehouse is a centralized repository that stores large volumes of integrated, historical data from multiple sources to support business intelligence, reporting, and data analysis.
What are the main differences between a data lake and a data warehouse?
A data lake stores raw, unstructured, and semi-structured data in its native format, while a data warehouse stores structured, processed, and curated data optimized for analysis and reporting. Data lakes offer high scalability and flexibility for big data and machine learning, whereas data warehouses provide fast query performance and support for business intelligence. Data lakes use technologies like Hadoop and Amazon S3, while data warehouses rely on systems like Amazon Redshift, Google BigQuery, or Snowflake.
What types of data are stored in a data lake?
A data lake stores structured data, semi-structured data, unstructured data, and binary data, including logs, social media feeds, videos, images, sensor data, and transactional records.
How is data structured in a data warehouse?
Data in a data warehouse is structured using a dimensional model, primarily consisting of fact tables and dimension tables organized in star or snowflake schemas to optimize query performance and support efficient data analysis.
What are the common use cases for data lakes?
Common use cases for data lakes include big data analytics, machine learning model training, real-time data processing, data archiving and backup, and centralized storage for diverse structured and unstructured data.
What are the advantages and disadvantages of data lakes and data warehouses?
Data lakes offer flexible storage of raw, unstructured data with high scalability and cost-effectiveness but suffer from complex data governance and slower query performance. Data warehouses provide structured, processed data optimized for fast queries and analytics but require expensive storage and rigid schema design, limiting flexibility.