Overfitting occurs when a machine learning model learns noise and details from the training data, resulting in high accuracy on training but poor generalization to new data. Underfitting happens when the model is too simple to capture the underlying patterns, leading to low accuracy both on training and unseen data. Explore further to understand techniques for balancing model complexity to improve prediction performance.
Main Difference
Overfitting occurs when a machine learning model learns the training data too well, capturing noise and details that do not generalize to new data, resulting in high accuracy on training sets but poor performance on unseen data. Underfitting happens when the model is too simple to capture the underlying patterns in the data, leading to low accuracy both on training and test sets. Overfitting is often addressed using techniques like cross-validation, regularization (L1, L2), and pruning, while underfitting may require increasing model complexity or feature engineering. Balancing bias and variance is critical for avoiding both overfitting and underfitting in predictive modeling.
Connection
Overfitting and underfitting are connected through their impact on a model's generalization ability, where overfitting occurs when a model captures noise in the training data, leading to high variance and poor performance on unseen data, while underfitting happens when a model is too simple to capture the underlying patterns, causing high bias and low accuracy even on training data. Both conditions degrade predictive performance, highlighting the need for a balanced model complexity achieved through techniques like cross-validation, regularization, and selecting appropriate features. Proper tuning of hyperparameters, such as learning rate and model depth, directly influences the trade-off between overfitting and underfitting to optimize machine learning outcomes.
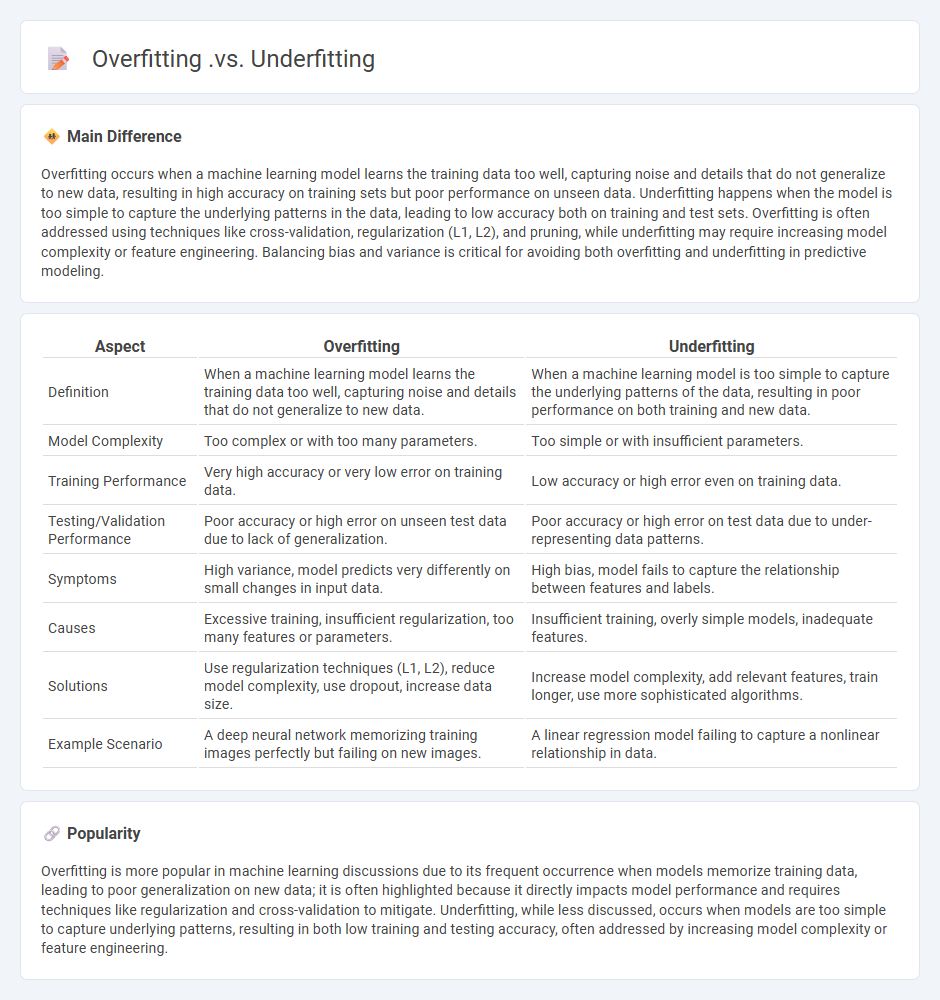
Comparison Table
| Aspect | Overfitting | Underfitting |
|---|---|---|
| Definition | When a machine learning model learns the training data too well, capturing noise and details that do not generalize to new data. | When a machine learning model is too simple to capture the underlying patterns of the data, resulting in poor performance on both training and new data. |
| Model Complexity | Too complex or with too many parameters. | Too simple or with insufficient parameters. |
| Training Performance | Very high accuracy or very low error on training data. | Low accuracy or high error even on training data. |
| Testing/Validation Performance | Poor accuracy or high error on unseen test data due to lack of generalization. | Poor accuracy or high error on test data due to under-representing data patterns. |
| Symptoms | High variance, model predicts very differently on small changes in input data. | High bias, model fails to capture the relationship between features and labels. |
| Causes | Excessive training, insufficient regularization, too many features or parameters. | Insufficient training, overly simple models, inadequate features. |
| Solutions | Use regularization techniques (L1, L2), reduce model complexity, use dropout, increase data size. | Increase model complexity, add relevant features, train longer, use more sophisticated algorithms. |
| Example Scenario | A deep neural network memorizing training images perfectly but failing on new images. | A linear regression model failing to capture a nonlinear relationship in data. |
Model Complexity
Model complexity in computer science quantifies the intricacy of algorithms, often measured by time complexity and space complexity which impact computational efficiency. It plays a critical role in areas like machine learning, where models with high complexity may overfit data, reducing generalization performance. Techniques such as regularization and pruning help control model complexity to optimize accuracy and resource utilization. Evaluating complexity involves analyzing algorithmic performance using Big O notation to predict scalability with input size.
Generalization
Generalization in computer science refers to the process of extracting shared characteristics from multiple specific instances to create a broader, more abstract concept or function. It is fundamental in object-oriented programming, enabling the creation of superclass hierarchies that encapsulate common attributes and methods shared by subclasses. This abstraction improves code reusability and maintainability by reducing redundancy and facilitating polymorphism. Prominent programming languages like Java, C++, and Python extensively utilize generalization for efficient software design and development.
Bias-Variance Tradeoff
The bias-variance tradeoff is a fundamental concept in machine learning and computer science that describes the balance between a model's error due to bias and variance. High bias models tend to oversimplify the data, leading to underfitting, while high variance models capture noise as if it were signal, resulting in overfitting. Techniques like cross-validation, regularization (e.g., Lasso, Ridge), and ensemble methods such as Random Forest help manage this tradeoff to improve model generalization. Understanding and optimizing this tradeoff enhances predictive performance and robustness in algorithms used for classification and regression tasks.
Training vs. Testing Error
Training error measures the accuracy of a machine learning model on the dataset used for training, reflecting how well the model has learned the underlying patterns. Testing error evaluates the model's performance on new, unseen data, indicating its generalization capability. A low training error paired with a high testing error often signals overfitting, where the model memorizes the training data but fails to generalize. Optimizing for minimal testing error is critical in computer science to ensure robust and reliable predictive models.
Regularization
Regularization in computer science improves model performance by preventing overfitting during machine learning training. Techniques like L1 and L2 regularization add penalty terms to loss functions, reducing model complexity and enhancing generalization on unseen data. Dropout regularization randomly omits neurons during training to promote robustness in neural networks. Effective regularization is essential for achieving reliable predictions in applications such as image recognition and natural language processing.
Source and External Links
### OverfittingOverfitting vs. Underfitting Explained - Overfitting occurs when a model is too complex and fits the training data too closely, resulting in poor generalization.
### UnderfittingWhat Is Overfitting vs. Underfitting? - Underfitting happens when a model is too simple and fails to capture the underlying patterns in the data, leading to poor performance on both training and test data.
### Overfitting vs Underfitting SummaryOverfitting vs. Underfitting: What's the Difference? - Overfitting is characterized by high model complexity and poor generalization, while underfitting is marked by model simplicity and inability to learn data patterns.
FAQs
What is overfitting in machine learning?
Overfitting in machine learning occurs when a model learns noise and details from the training data to an extent that it negatively impacts its performance on new, unseen data.
What is underfitting in machine learning?
Underfitting in machine learning occurs when a model is too simple to capture the underlying patterns of the training data, resulting in poor performance on both training and test datasets.
How do overfitting and underfitting differ?
Overfitting occurs when a model learns noise and details in the training data, resulting in poor generalization to new data, while underfitting happens when a model is too simple to capture the underlying patterns and performs poorly on both training and test data.
What causes overfitting in a model?
Overfitting in a model is caused by excessively complex models that learn noise and random fluctuations in the training data instead of general patterns, often due to insufficient training data, high model complexity, or inadequate regularization.
What causes underfitting in a model?
Underfitting in a model is caused by insufficient model complexity, inadequate training data, poor feature selection, or excessive regularization.
How can overfitting be prevented?
Overfitting can be prevented by using techniques such as cross-validation, regularization (L1, L2), dropout, early stopping, data augmentation, and increasing training data diversity.
How can underfitting be resolved?
Underfitting can be resolved by increasing model complexity, adding relevant features, reducing regularization, or training longer with more data.