Instruction-Level Parallelism (ILP) exploits fine-grained parallelism by overlapping the execution of multiple instructions within a single CPU core, enhancing instruction throughput. Thread-Level Parallelism (TLP) leverages multiple threads running concurrently across multiple cores or processors, improving overall program execution efficiency. Explore the differences and benefits of ILP and TLP to optimize computing performance.
Main Difference
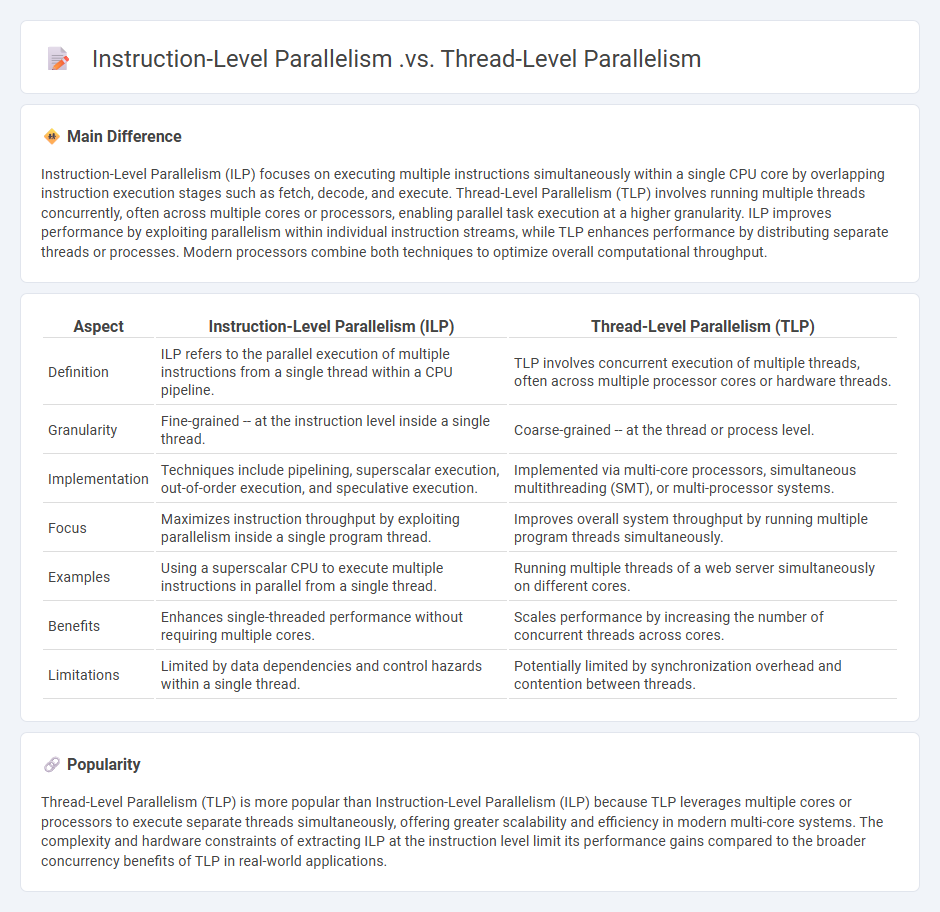
Instruction-Level Parallelism (ILP) focuses on executing multiple instructions simultaneously within a single CPU core by overlapping instruction execution stages such as fetch, decode, and execute. Thread-Level Parallelism (TLP) involves running multiple threads concurrently, often across multiple cores or processors, enabling parallel task execution at a higher granularity. ILP improves performance by exploiting parallelism within individual instruction streams, while TLP enhances performance by distributing separate threads or processes. Modern processors combine both techniques to optimize overall computational throughput.
Connection
Instruction-Level Parallelism (ILP) and Thread-Level Parallelism (TLP) both enhance computing performance by executing multiple operations concurrently, with ILP focusing on parallel execution within a single processor by overlapping instructions, while TLP distributes tasks across multiple threads running on separate cores or processors. These parallelism techniques complement each other as ILP maximizes the efficiency of individual processors, whereas TLP scales performance by leveraging multiple processing units to handle concurrent threads. The combined use of ILP and TLP significantly improves throughput and responsiveness in modern multi-core architectures and parallel computing environments.
Comparison Table
| Aspect | Instruction-Level Parallelism (ILP) | Thread-Level Parallelism (TLP) |
|---|---|---|
| Definition | ILP refers to the parallel execution of multiple instructions from a single thread within a CPU pipeline. | TLP involves concurrent execution of multiple threads, often across multiple processor cores or hardware threads. |
| Granularity | Fine-grained -- at the instruction level inside a single thread. | Coarse-grained -- at the thread or process level. |
| Implementation | Techniques include pipelining, superscalar execution, out-of-order execution, and speculative execution. | Implemented via multi-core processors, simultaneous multithreading (SMT), or multi-processor systems. |
| Focus | Maximizes instruction throughput by exploiting parallelism inside a single program thread. | Improves overall system throughput by running multiple program threads simultaneously. |
| Examples | Using a superscalar CPU to execute multiple instructions in parallel from a single thread. | Running multiple threads of a web server simultaneously on different cores. |
| Benefits | Enhances single-threaded performance without requiring multiple cores. | Scales performance by increasing the number of concurrent threads across cores. |
| Limitations | Limited by data dependencies and control hazards within a single thread. | Potentially limited by synchronization overhead and contention between threads. |
Data Dependency
Data dependency in computer architecture refers to the relationship between instructions where the execution of one instruction depends on the data result of a previous instruction. It affects instruction scheduling, pipeline design, and overall system performance by potentially causing stalls or hazards. There are several types of data dependencies, including true dependency (read-after-write), anti-dependency (write-after-read), and output dependency (write-after-write). Detecting and managing these dependencies is crucial for optimizing processor throughput and minimizing latency in parallel processing environments.
Pipeline Hazards
Pipeline hazards in computer architecture disrupt the smooth execution of instruction pipelines, causing delays or stalls. They are primarily classified into three types: structural hazards, which occur due to resource conflicts; data hazards, resulting from dependencies between instructions; and control hazards, caused by branch instructions altering the program flow. Effective techniques to mitigate these hazards include forwarding, pipeline interlocks, and branch prediction algorithms. Modern processors leverage out-of-order execution and speculative execution to minimize the impact of pipeline hazards on performance.
Superscalar Architecture
Superscalar architecture enables a processor to execute multiple instructions per clock cycle by employing multiple execution units and parallel pipelines. It improves instruction-level parallelism and enhances CPU performance by dispatching several instructions simultaneously, reducing instruction latency. Modern superscalar processors integrate dynamic scheduling, out-of-order execution, and branch prediction to optimize throughput and resource utilization. Prominent examples include Intel's Pentium Pro and AMD's Zen microarchitecture, which leverage superscalar design for efficient computation.
Multithreading
Multithreading in computer science allows a single process to manage multiple threads concurrently, enhancing CPU utilization and improving application performance. Modern operating systems such as Windows, Linux, and macOS support preemptive multithreading, enabling efficient context switching. Programming languages like Java, C++, and Python provide robust multithreading APIs to create responsive and scalable applications. Hardware advancements including multi-core processors have further accelerated multithreaded processing capabilities.
Context Switching
Context switching in computer systems refers to the process of storing and restoring the state of a CPU so that multiple processes can share a single processor efficiently. This technique enables multitasking by allowing the operating system to switch between different threads or processes rapidly, ensuring fair CPU allocation. The context switch involves saving the process context, including registers, program counter, and memory maps, to a process control block (PCB) before loading the context of the next scheduled task. Efficient context switching minimizes latency and overhead, which is crucial for achieving high performance in real-time operating systems and modern multitasking environments.
Source and External Links
What is the difference between instruction-level parallelism and thread-level parallelism? - Instruction-Level Parallelism (ILP) involves executing multiple instructions from a single thread simultaneously within a processor, whereas Thread-Level Parallelism (TLP) executes multiple threads concurrently across multiple processors or cores, enhancing performance by running independent tasks in parallel.
Instruction-Level Parallelism (ILP) vs Thread-Level Parallelism (TLP) - ILP executes multiple instructions in a single cycle within a single thread using wide-issue superscalar processors, while TLP runs different threads in parallel on multiprocessors, suitable for workloads like databases and graphics.
Maximize Speed with Thread Level Parallelism In Computing - Lenovo - TLP includes running multiple threads simultaneously across multiple cores to improve performance and resource utilization, in contrast to ILP, which focuses on parallel execution of instructions within a single thread on a single core.
FAQs
What is parallelism in computing?
Parallelism in computing is the simultaneous execution of multiple processes or threads to increase computational speed and efficiency.
What is instruction-level parallelism?
Instruction-level parallelism (ILP) is the ability of a processor to execute multiple instructions simultaneously by overlapping their execution phases using techniques such as pipelining, superscalar execution, and out-of-order execution.
What is thread-level parallelism?
Thread-level parallelism (TLP) is the concurrent execution of multiple threads within a single process or across multiple processes to improve performance and resource utilization in multi-core or multiprocessor systems.
How do instruction-level and thread-level parallelism differ?
Instruction-level parallelism (ILP) exploits simultaneous execution of multiple instructions within a single processor core by overlapping instruction execution stages, while thread-level parallelism (TLP) involves running multiple threads concurrently on multiple cores or processors to enhance overall throughput.
What are the benefits of instruction-level parallelism?
Instruction-level parallelism improves CPU throughput by executing multiple instructions simultaneously, reducing latency, enhancing performance, increasing resource utilization, and enabling faster program execution.
What are the advantages of thread-level parallelism?
Thread-level parallelism improves system throughput, reduces execution time, enhances resource utilization, and enables better scalability in multicore processors.
When should you use thread-level parallelism instead of instruction-level parallelism?
Use thread-level parallelism when executing multiple independent tasks or processes concurrently improves performance more effectively than overlapping instructions within a single thread.