Hash join efficiently handles large datasets by partitioning tables into hash buckets, resulting in faster join operations compared to nested loop join, which compares each row in one table with every row in another, leading to higher computational costs. Nested loop join performs better on small or indexed datasets but suffers from performance degradation as data size grows, making hash join preferable for complex queries in big data environments. Explore deeper to understand which join algorithm best suits your database optimization needs.
Main Difference
Hash join excels in handling large, unsorted datasets by creating a hash table on the smaller relation and probing it with the larger relation, resulting in efficient equality joins. Nested loop join compares each row of the outer table to every row of the inner table, making it suitable for small tables or non-equality join conditions but less efficient for large datasets. Hash join performs best with equi-joins and large datasets due to its average linear time complexity, while nested loop join can handle various join predicates but often suffers from quadratic time complexity. The choice depends on dataset size, join condition, and availability of indexes.
Connection
Hash join and nested loop join are both fundamental algorithms for executing join operations in relational databases, where nested loop join compares each tuple from one relation with every tuple from the other, resulting in higher complexity for large datasets. Hash join improves efficiency by partitioning one or both relations into hash buckets based on join keys, enabling faster matching through hash table lookups. Both methods aim to combine tuples based on common attributes but differ significantly in performance and suitability depending on data size and indexing.
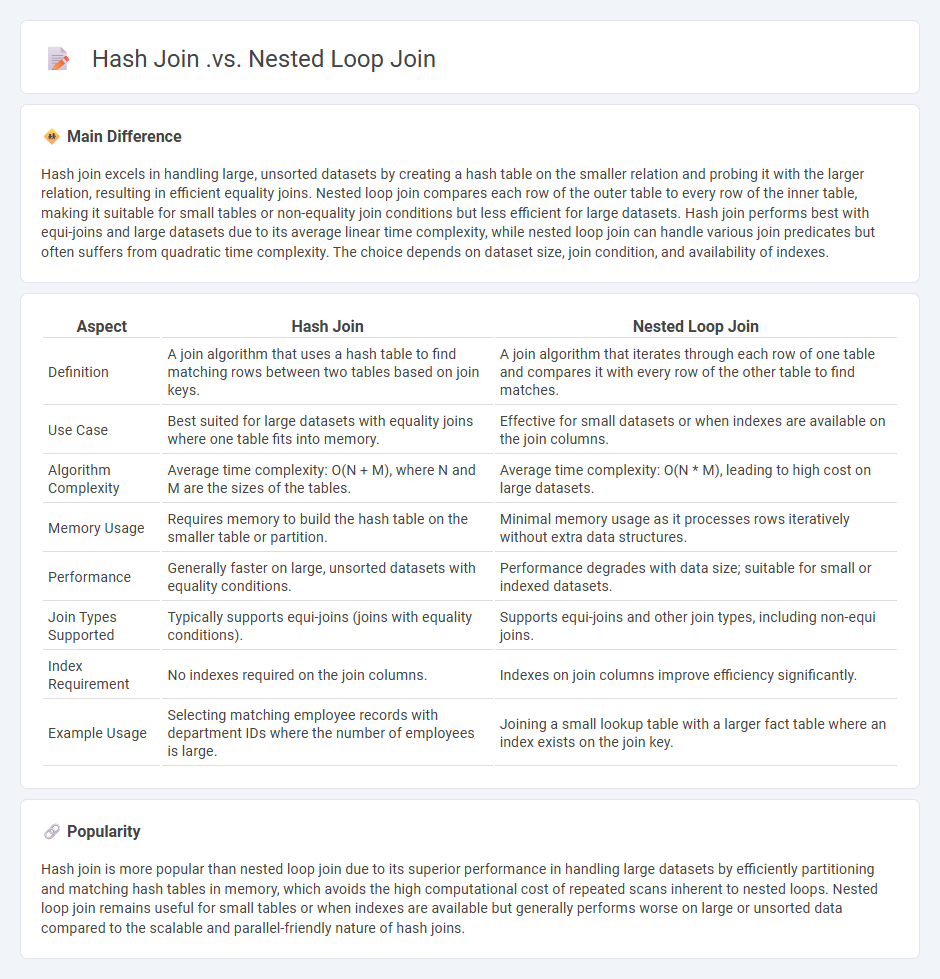
Comparison Table
| Aspect | Hash Join | Nested Loop Join |
|---|---|---|
| Definition | A join algorithm that uses a hash table to find matching rows between two tables based on join keys. | A join algorithm that iterates through each row of one table and compares it with every row of the other table to find matches. |
| Use Case | Best suited for large datasets with equality joins where one table fits into memory. | Effective for small datasets or when indexes are available on the join columns. |
| Algorithm Complexity | Average time complexity: O(N + M), where N and M are the sizes of the tables. | Average time complexity: O(N * M), leading to high cost on large datasets. |
| Memory Usage | Requires memory to build the hash table on the smaller table or partition. | Minimal memory usage as it processes rows iteratively without extra data structures. |
| Performance | Generally faster on large, unsorted datasets with equality conditions. | Performance degrades with data size; suitable for small or indexed datasets. |
| Join Types Supported | Typically supports equi-joins (joins with equality conditions). | Supports equi-joins and other join types, including non-equi joins. |
| Index Requirement | No indexes required on the join columns. | Indexes on join columns improve efficiency significantly. |
| Example Usage | Selecting matching employee records with department IDs where the number of employees is large. | Joining a small lookup table with a larger fact table where an index exists on the join key. |
Join Algorithm
The Join algorithm in computer science is a fundamental operation in database management systems used to combine rows from two or more tables based on related columns. Common types of join algorithms include nested loop join, sort-merge join, and hash join, each optimized for different data distributions and sizes. Hash join often provides high performance for large, unsorted datasets by using a hash table to match join keys efficiently. Understanding the computational complexity and memory usage of these algorithms is essential for query optimization and improving database performance.
Performance
Computer performance measures the speed and efficiency with which a computer completes tasks, influenced by factors such as CPU clock speed, number of cores, RAM size, and storage type. Modern processors, like Intel's Core i9 or AMD's Ryzen 9, feature multiple cores and high clock speeds exceeding 5 GHz to handle parallel processing demands. Solid State Drives (SSD) provide faster data access times compared to traditional Hard Disk Drives (HDD), significantly improving system responsiveness and boot times. Benchmark tests like Geekbench or PassMark quantify computer performance, helping users compare processing power and overall system efficiency.
Data Size
Data size in computers is measured in bytes, with common units including kilobyte (KB), megabyte (MB), gigabyte (GB), and terabyte (TB). One kilobyte equals 1,024 bytes, while one megabyte consists of 1,024 kilobytes, and one gigabyte contains 1,024 megabytes. Modern computers commonly use solid-state drives (SSD) or hard disk drives (HDD) with storage capacities ranging from 256 GB to multiple terabytes. Accurate understanding of data size units is essential for efficient memory allocation, data storage, and system performance optimization.
Index Requirement
Index requirement in computer systems refers to the necessity of creating efficient data structures for fast data retrieval and query optimization in databases and search engines. Indexes, such as B-trees and hash tables, significantly reduce search time by allowing direct access to data entries instead of scanning entire datasets. Modern databases like MySQL and MongoDB rely on well-designed indexes to improve performance for large volumes of read/write operations. Proper understanding of index types and their maintenance is crucial to balance speed and storage overhead in computer applications.
Memory Usage
Memory usage in computers refers to the amount of RAM actively utilized by running programs and the operating system at any given time. Efficient memory management ensures faster data access and improved overall system performance, reducing latency and preventing bottlenecks. Modern systems incorporate virtual memory techniques, combining physical RAM with disk storage to handle larger workloads seamlessly. Monitoring tools like Task Manager or top provide real-time insights into memory allocation, aiding in optimizing resource usage.
Source and External Links
Difference Between Nested Loop Join and Hash Join - GeeksforGeeks - Nested Loop Join is simpler and faster for small tables, performing inner loop processing for each outer row, while Hash Join is better for joining larger tables by building a hash table on the smaller table and probing it for matches, though it uses more RAM and more comparisons.
Nested Join vs Hash Join vs Merge Join in PostgreSQL - Nested Loop Join works by iterating through each row in the outer table and comparing with each in the inner table, suitable for small datasets, whereas Hash Join creates a hash table for the smaller inner table and probes it with the outer table rows, making it more efficient for larger tables.
Nested-loop joins versus hash joins - IBM - Hash joins have a higher cost to retrieve the first row due to hash table building but can be faster overall for large data, while nested-loop joins perform better for queries optimized for first-row retrieval using indexes, making nested loops preferable for smaller data sets or indexed joins.
FAQs
What is a join operation in databases?
A join operation in databases combines rows from two or more tables based on a related column, typically using keys, to produce a unified dataset.
What is a hash join?
A hash join is a database algorithm that uses a hash table to efficiently match rows from two tables based on join keys.
What is a nested loop join?
A nested loop join is a database operation that iterates each row of one table (outer loop) and for each row, scans all rows of another table (inner loop) to find matching pairs based on a join condition.
How do hash join and nested loop join differ in performance?
Hash join outperforms nested loop join on large, unsorted datasets by hashing one table for quick lookups, while nested loop join is efficient for small or indexed tables due to its iterative comparison approach.
When should you use a hash join?
Use a hash join when joining large, unsorted tables on equality conditions, especially if there are no suitable indexes available.
When is nested loop join preferred?
Nested loop join is preferred when joining small tables, when there are indexes on the join columns, or when the join condition is highly selective, making it more efficient than other join algorithms.
What are the limitations of hash join and nested loop join?
Hash join is limited by memory size since large datasets require more memory for hash tables, causing performance degradation or spilling to disk. Nested loop join suffers from poor performance with large datasets due to its O(n*m) time complexity, making it inefficient without indexes or small input sizes.