Opaque pointers hide the internal structure of data types, promoting encapsulation and reducing compilation dependencies in software development. Transparent pointers expose the data structure, allowing direct access and manipulation, which can improve performance but increase coupling between components. Explore the advantages and use cases of opaque and transparent pointers to determine the best approach for your programming projects.
Main Difference
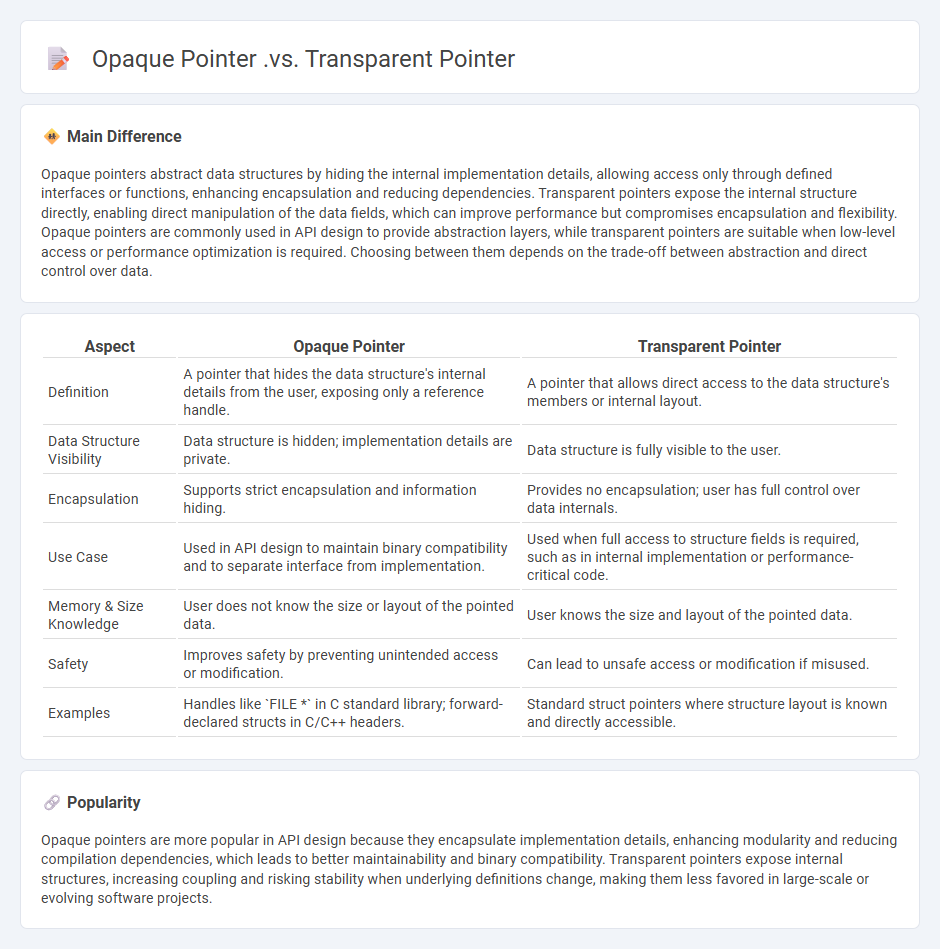
Opaque pointers abstract data structures by hiding the internal implementation details, allowing access only through defined interfaces or functions, enhancing encapsulation and reducing dependencies. Transparent pointers expose the internal structure directly, enabling direct manipulation of the data fields, which can improve performance but compromises encapsulation and flexibility. Opaque pointers are commonly used in API design to provide abstraction layers, while transparent pointers are suitable when low-level access or performance optimization is required. Choosing between them depends on the trade-off between abstraction and direct control over data.
Connection
Opaque pointers encapsulate data by hiding its implementation details, while transparent pointers expose the underlying data structure, facilitating direct access. Both pointer types manage data abstraction levels in programming, influencing encapsulation and type safety. The connection lies in their complementary roles in balancing information hiding with accessibility for different programming needs.
Comparison Table
| Aspect | Opaque Pointer | Transparent Pointer |
|---|---|---|
| Definition | A pointer that hides the data structure's internal details from the user, exposing only a reference handle. | A pointer that allows direct access to the data structure's members or internal layout. |
| Data Structure Visibility | Data structure is hidden; implementation details are private. | Data structure is fully visible to the user. |
| Encapsulation | Supports strict encapsulation and information hiding. | Provides no encapsulation; user has full control over data internals. |
| Use Case | Used in API design to maintain binary compatibility and to separate interface from implementation. | Used when full access to structure fields is required, such as in internal implementation or performance-critical code. |
| Memory & Size Knowledge | User does not know the size or layout of the pointed data. | User knows the size and layout of the pointed data. |
| Safety | Improves safety by preventing unintended access or modification. | Can lead to unsafe access or modification if misused. |
| Examples | Handles like `FILE *` in C standard library; forward-declared structs in C/C++ headers. | Standard struct pointers where structure layout is known and directly accessible. |
Data Encapsulation
Data encapsulation in computer science refers to the bundling of data with the methods that operate on that data within a single unit, typically a class in object-oriented programming. This concept enforces access restrictions by using access specifiers like private, protected, and public, which enhance data security and integrity. Encapsulation helps maintain code modularity and reduces complexity by hiding internal object details from the outside world. Commonly implemented in languages such as Java, C++, and Python, data encapsulation supports software maintainability and robustness.
Implementation Hiding
Implementation hiding in computer science refers to the principle of concealing the internal details of a module or object to protect its complexity and enhance modularity. This technique limits direct access to specific components, exposing only necessary interfaces to users, which reduces interdependencies and improves maintainability. Programming languages like Java and C++ support implementation hiding through access modifiers such as private, protected, and public. Effective implementation hiding leads to more secure and robust software architecture by isolating changes and minimizing the impact on other system parts.
Type Safety
Type safety in computer science ensures that operations in a programming language are performed on compatible data types, minimizing runtime errors and enhancing code reliability. Statically typed languages like Java and C++ enforce type safety at compile time by checking variable types before execution, while dynamically typed languages like Python implement runtime type checks. Type-safe languages prevent common bugs such as type errors, buffer overflows, and invalid memory access, contributing to software security and robustness. Tools like type inference and static analysis further strengthen type safety by automatically verifying code correctness and detecting inconsistencies early in the development process.
ABI Stability
ABI stability in computer systems ensures consistent binary interfaces across software updates, enabling compatibility between different versions of applications and operating systems. This stability facilitates seamless integration of libraries and modules without requiring recompilation, reducing development time and maintenance costs. Key factors influencing ABI stability include data structure layouts, calling conventions, and symbol versioning, which must remain consistent to avoid runtime failures. Operating systems like Linux and Windows implement strict ABI policies to support diverse software ecosystems and long-term platform reliability.
Direct Access
Direct access in computer systems refers to the ability to retrieve or store data at any physical location on a storage device without sequentially reading through other data. This method, commonly associated with random-access memory (RAM) and direct-access storage devices like hard drives and solid-state drives, enables faster data retrieval compared to sequential access methods. Direct access significantly improves system performance by reducing latency in data read/write operations, crucial for applications requiring real-time processing or rapid data manipulation. Technologies like NVMe SSDs leverage direct access to enhance input/output operations per second (IOPS), benefiting computing tasks ranging from database management to high-frequency trading systems.
Source and External Links
Practical Design Patterns: Opaque Pointers and Objects in C - An opaque pointer in C refers to a pointer to a data structure whose contents are not visible to the user; only the pointer type is exposed in the header, hiding implementation details and allowing encapsulation, while a transparent pointer would expose the structure fully, revealing its members.
The importance of opaque types - Flameeyes's Weblog - A transparent type exposes its internal data to the code using it, whereas an opaque type hides this data, typically by forward declaring a struct in C without revealing the internal fields, helping enforce information hiding and abstraction.
Opaque data type - Wikipedia - Opaque data types are data types whose internal representation is hidden from the user (not transparent), often used in implementing abstract data types to achieve modularity and encapsulation, while transparent types have visible representations.
FAQs
What is a pointer in programming?
A pointer in programming is a variable that stores the memory address of another variable, allowing indirect access and manipulation of that variable's value.
What is an opaque pointer?
An opaque pointer is a pointer type in programming that hides the internal structure of the data it references, providing abstraction and encapsulation by exposing only the pointer without revealing the underlying data details.
What is a transparent pointer?
A transparent pointer is a smart pointer in programming that behaves like a regular raw pointer, allowing implicit conversions and operations without requiring explicit casts.
How do opaque and transparent pointers differ?
Opaque pointers hide the internal structure of the data they reference, allowing access only through defined interfaces, while transparent pointers expose the underlying data structure, enabling direct access and manipulation.
When should you use an opaque pointer?
Use an opaque pointer to hide implementation details in a C or C++ API, enabling encapsulation and reducing compilation dependencies by exposing only a forward-declared struct pointer in the interface.
What are the benefits of transparent pointers?
Transparent pointers improve memory safety, enable efficient memory management, simplify pointer arithmetic, and facilitate debugging by clearly representing pointer ownership and usage in software development.
What are some common use cases for opaque pointers?
Opaque pointers are commonly used for data encapsulation in APIs to hide implementation details, enable forward declarations to reduce compilation dependencies, provide binary compatibility across software versions, and improve modularity by separating interface and implementation.