Parsing involves analyzing a string of symbols to determine its grammatical structure according to a formal grammar, while lexing, or lexical analysis, breaks down the input into a sequence of tokens representing meaningful elements like keywords and operators. Lexers simplify complex code into manageable pieces, enabling parsers to construct syntax trees for interpreters or compilers. Explore further to understand how these processes enable efficient programming language interpretation and compilation.
Main Difference
Lexing, or lexical analysis, involves the process of converting a sequence of characters into a sequence of tokens, which represent basic syntactic units like keywords, operators, and identifiers. Parsing takes these tokens as input and analyzes their grammatical structure according to a formal grammar, constructing a parse tree or abstract syntax tree (AST). Lexing focuses on token generation and pattern recognition, while parsing deals with syntax validation and hierarchical structure formation. Together, they form essential stages in compiling or interpreting programming languages.
Connection
Parsing and lexing are interconnected processes in compiler design where lexing, or lexical analysis, transforms raw source code into tokens, serving as the initial phase. Parsing then takes these tokens to construct a syntax tree, interpreting the grammatical structure according to the language's syntax rules. Together, these stages enable efficient translation and error detection in source code processing.
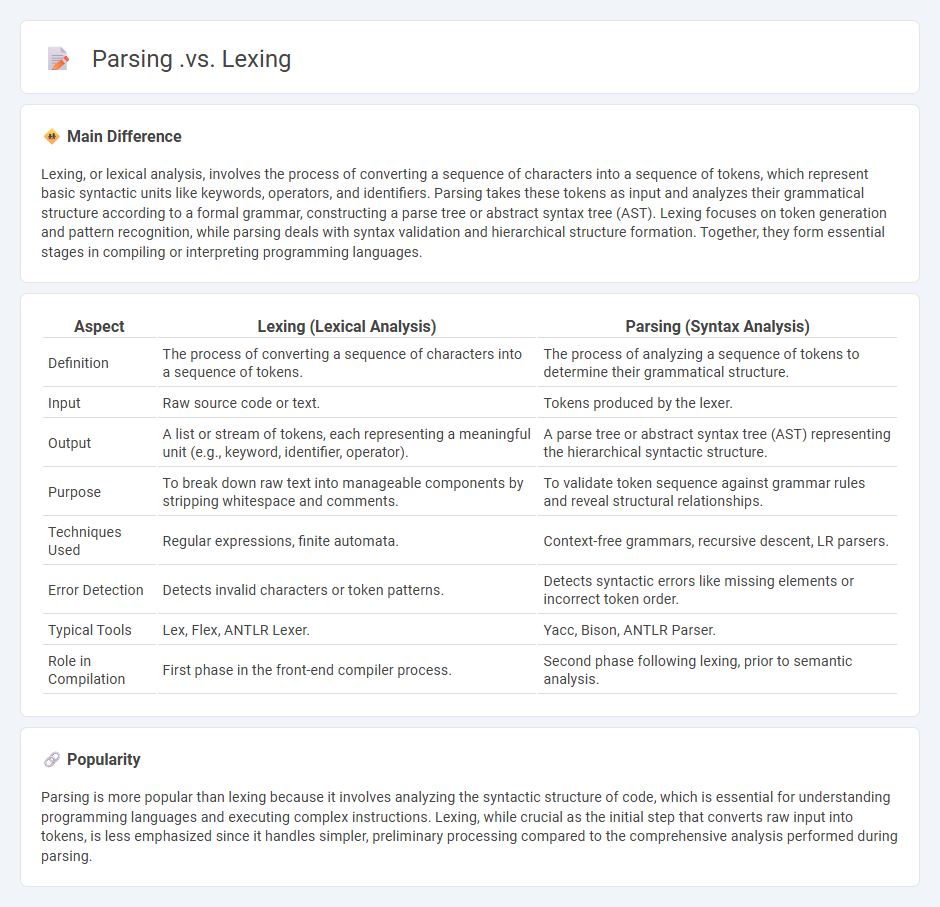
Comparison Table
| Aspect | Lexing (Lexical Analysis) | Parsing (Syntax Analysis) |
|---|---|---|
| Definition | The process of converting a sequence of characters into a sequence of tokens. | The process of analyzing a sequence of tokens to determine their grammatical structure. |
| Input | Raw source code or text. | Tokens produced by the lexer. |
| Output | A list or stream of tokens, each representing a meaningful unit (e.g., keyword, identifier, operator). | A parse tree or abstract syntax tree (AST) representing the hierarchical syntactic structure. |
| Purpose | To break down raw text into manageable components by stripping whitespace and comments. | To validate token sequence against grammar rules and reveal structural relationships. |
| Techniques Used | Regular expressions, finite automata. | Context-free grammars, recursive descent, LR parsers. |
| Error Detection | Detects invalid characters or token patterns. | Detects syntactic errors like missing elements or incorrect token order. |
| Typical Tools | Lex, Flex, ANTLR Lexer. | Yacc, Bison, ANTLR Parser. |
| Role in Compilation | First phase in the front-end compiler process. | Second phase following lexing, prior to semantic analysis. |
Tokenization
Tokenization in computer science refers to the process of breaking down text into smaller units called tokens, which can be words, phrases, or symbols. This procedure is fundamental in natural language processing (NLP) tasks such as text analysis, information retrieval, and machine learning. Tools like NLTK, SpaCy, and Stanford NLP provide efficient tokenization algorithms supporting languages including English, Spanish, and Chinese. Accurate tokenization enhances the performance of applications like sentiment analysis, language translation, and named entity recognition.
Syntax Analysis
Syntax analysis, also known as parsing, is a crucial phase in compiler design that involves analyzing the source code's grammatical structure based on a formal grammar, typically context-free grammars. This process generates a parse tree or abstract syntax tree (AST) representing the hierarchical syntactic structure of the program. Common parsing techniques include top-down parsers like recursive descent and predictive parsers, as well as bottom-up parsers such as LR, SLR, and LALR parsers. Accurate syntax analysis enables subsequent compiler phases like semantic analysis and code generation to function correctly by ensuring source code conforms to the language's syntax rules.
Abstract Syntax Tree (AST)
Abstract Syntax Tree (AST) represents the hierarchical syntactic structure of source code in computer science, crucial for compilers and interpreters. It abstracts away syntactic details like punctuation and focuses on the grammar and semantics of programming languages. ASTs enable efficient code analysis, optimization, and transformation by breaking programs into nested nodes representing language constructs. Modern development tools leverage ASTs for automated refactoring, syntax highlighting, and static code analysis.
Grammar Rules
In computer science, grammar rules define syntax structures for programming languages, specifying valid sequences of symbols and tokens. Context-free grammars (CFG) are widely used to describe programming language syntax, employing production rules with non-terminals, terminals, and a start symbol. Parsing algorithms like LL and LR parsers analyze these grammar rules to validate code and generate syntax trees. Well-defined grammar is essential for compiler design, enabling accurate code interpretation and error detection.
Lexical Analyzer
A lexical analyzer, also known as a lexer or scanner, is a crucial component in compiler design that processes source code by converting a sequence of characters into meaningful tokens. It identifies keywords, identifiers, operators, and syntax symbols based on lexical rules defined by regular expressions or finite automata. This component enhances parsing efficiency by reducing the input complexity, enabling syntax analyzers to work with token streams rather than raw characters. Tools like Lex and Flex automate lexical analyzer generation, facilitating robust compiler and interpreter development.
Source and External Links
Intro To Parsing & Lexing - This post explains the basics of lexing and parsing, including how lexing converts source code into tokens and parsing creates an abstract syntax tree (AST).
Lexical Analysis - Lexical analysis, or lexing, is the process of converting raw text into meaningful tokens, which are then used in parsing to analyze the syntax of the program.
Lexing and Parsing - Rust Compiler Development Guide - This guide describes how lexing turns strings into tokens and parsing converts these tokens into an abstract syntax tree (AST) for easier processing by the compiler.
FAQs
What is lexing in programming languages?
Lexing in programming languages is the process of converting a sequence of characters from source code into a sequence of tokens to facilitate parsing and compilation.
What is parsing and how does it work?
Parsing is the process of analyzing a string of symbols, either in natural language or computer languages, to determine its grammatical structure according to a formal grammar. It works by breaking down the input into its constituent parts, identifying syntactic elements like phrases or tokens, and constructing a parse tree or abstract syntax tree that represents the hierarchical relationship among these elements.
How do lexers and parsers differ in function?
Lexers tokenize input text into meaningful symbols, while parsers analyze token sequences to construct hierarchical syntactic structures.
What are the outputs of a lexer and a parser?
A lexer outputs a sequence of tokens representing atomic syntactic units from the source code, while a parser outputs a parse tree or abstract syntax tree (AST) that represents the hierarchical syntactic structure of the tokens.
Why is lexing performed before parsing?
Lexing is performed before parsing to convert raw source code into a stream of tokens, simplifying and structuring the input for the parser to efficiently analyze syntax and grammar.
What are common tools for lexing and parsing?
Common tools for lexing and parsing include Flex, Lex, ANTLR, Bison, Yacc, and JavaCC.
How do errors differ between lexing and parsing?
Lexing errors occur during tokenization when invalid or unrecognized character sequences are encountered, while parsing errors arise from syntactic invalidities when the token sequence fails to conform to the grammar rules.