SIMD (Single Instruction, Multiple Data) and MIMD (Multiple Instruction, Multiple Data) are two fundamental parallel computing architectures optimizing processing efficiency. SIMD executes the same instruction across multiple data points simultaneously, ideal for tasks like image processing, while MIMD handles multiple instructions on different data sets concurrently, suited for complex, varied workloads such as simulations. Explore these architectures to understand their applications in enhancing computational performance.
Main Difference
SIMD (Single Instruction, Multiple Data) executes the same instruction across multiple data points simultaneously, making it ideal for parallel processing tasks like graphics rendering and vector computations. MIMD (Multiple Instruction, Multiple Data) allows independent execution of different instructions on separate data streams, enabling more flexible and complex parallelism found in multicore processors and distributed systems. SIMD architectures excel in data-level parallelism, while MIMD supports task-level parallelism for diverse workloads. This distinction influences performance optimization in applications such as scientific simulations and real-time systems.
Connection
SIMD (Single Instruction, Multiple Data) and MIMD (Multiple Instruction, Multiple Data) are parallel computing architectures designed to enhance processing efficiency. SIMD executes a single operation on multiple data points simultaneously, ideal for vectorized tasks like graphics processing. MIMD allows multiple processors to execute different instructions on different data streams concurrently, supporting complex, multitasking environments and distributed computing systems.
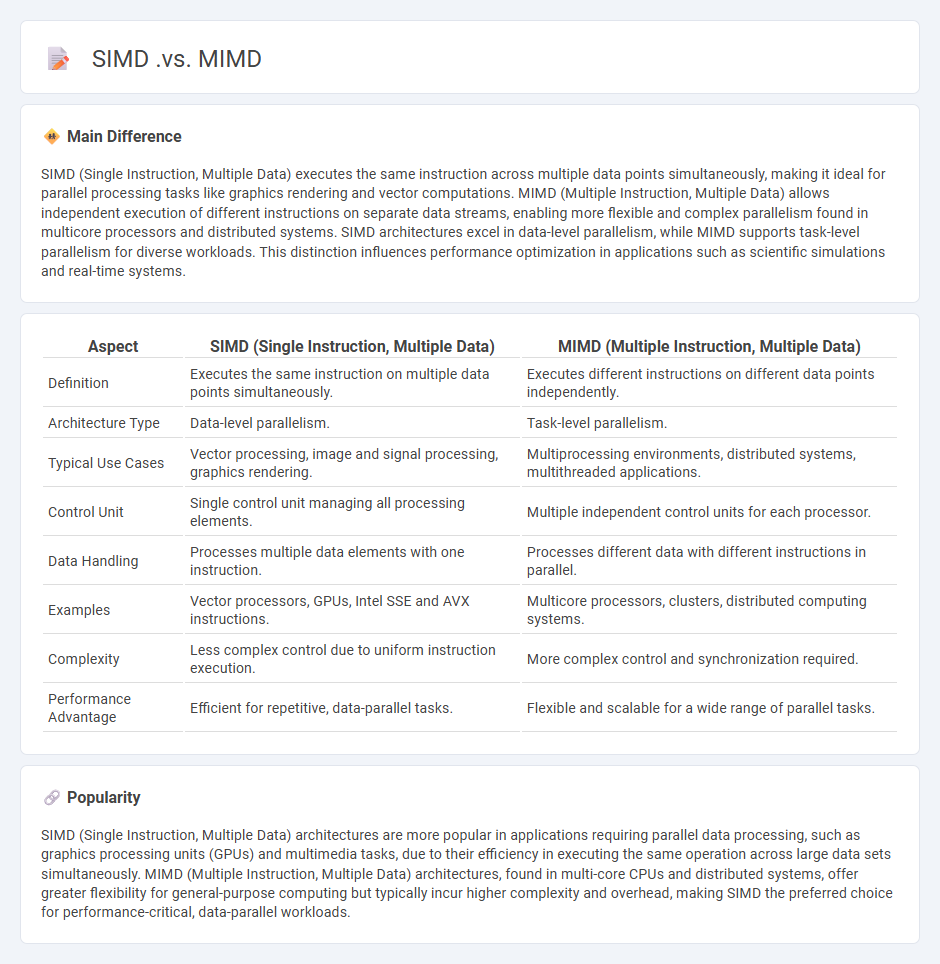
Comparison Table
| Aspect | SIMD (Single Instruction, Multiple Data) | MIMD (Multiple Instruction, Multiple Data) |
|---|---|---|
| Definition | Executes the same instruction on multiple data points simultaneously. | Executes different instructions on different data points independently. |
| Architecture Type | Data-level parallelism. | Task-level parallelism. |
| Typical Use Cases | Vector processing, image and signal processing, graphics rendering. | Multiprocessing environments, distributed systems, multithreaded applications. |
| Control Unit | Single control unit managing all processing elements. | Multiple independent control units for each processor. |
| Data Handling | Processes multiple data elements with one instruction. | Processes different data with different instructions in parallel. |
| Examples | Vector processors, GPUs, Intel SSE and AVX instructions. | Multicore processors, clusters, distributed computing systems. |
| Complexity | Less complex control due to uniform instruction execution. | More complex control and synchronization required. |
| Performance Advantage | Efficient for repetitive, data-parallel tasks. | Flexible and scalable for a wide range of parallel tasks. |
Parallelism
Parallelism in computer science refers to the simultaneous execution of multiple computations to increase efficiency and speed. It leverages multi-core processors, graphics processing units (GPUs), and distributed computing systems to perform tasks concurrently. Popular frameworks for parallel programming include OpenMP, MPI, and CUDA, enabling developers to optimize performance in data-intensive and computationally heavy applications. Effective parallelism reduces execution time significantly in applications like scientific simulations, machine learning, and big data analytics.
Instruction Stream
Instruction streams in computer architecture consist of a sequential flow of binary-coded instructions fetched from memory to be decoded and executed by the CPU. These streams enable the processor to perform operations by directing control signals to various components such as the ALU, registers, and memory units. Modern CPUs utilize techniques like pipelining and out-of-order execution to optimize instruction stream processing, enhancing overall performance and throughput. Effective management of instruction streams is crucial for reducing latency and maximizing computational efficiency in both single-core and multi-core systems.
Data Stream
Data stream in computer science refers to a continuous flow of data that is processed in real-time or near-real-time, enabling applications like video streaming, sensor data analysis, and network monitoring. Stream processing frameworks, such as Apache Kafka and Apache Flink, handle high-throughput and low-latency data streams, ensuring efficient computation and scalable analytics. Techniques like windowing and stateful processing are essential for managing infinite data sequences and extracting meaningful insights. Data stream models contrast with batch processing by focusing on incremental computation over constantly arriving data points.
Synchronization
Synchronization in computer systems ensures coordinated access to shared resources, preventing race conditions and data inconsistencies. Techniques such as mutexes, semaphores, and monitors manage concurrent processes and threads efficiently. Modern operating systems like Windows, Linux, and macOS incorporate advanced synchronization primitives to optimize performance in multicore processors. Proper synchronization is crucial in distributed systems and real-time applications for maintaining data integrity and system stability.
Scalability
Scalability in computer systems refers to the capacity to handle increasing workloads by adding resources such as CPU, memory, or storage without sacrificing performance. Vertical scalability involves upgrading hardware to improve a single system, while horizontal scalability entails adding more machines to distribute load efficiently. Cloud platforms like AWS and Azure provide elastic scalability, enabling dynamic resource allocation based on demand. Effective scalability ensures high availability and responsiveness in distributed computing environments and large-scale applications.
Source and External Links
Difference Between SIMD and MIMD - Tutorialspoint - SIMD (Single Instruction Multiple Data) applies one instruction to multiple data streams enabling high parallelism but less flexibility, whereas MIMD (Multiple Instruction Multiple Data) runs different instructions simultaneously on multiple data streams, offering more flexibility but less parallelism.
Difference between SIMD and MIMD - GeeksforGeeks - SIMD is efficient for uniform operations on large data sets such as image processing with simpler control, but limited flexibility, while MIMD supports diverse instructions and multitasking, resulting in higher performance and versatility.
A Deep Dive into SIMD and MIMD Architectures | HackerNoon - SIMD architectures excel at processing arrays or vectors with the same instruction simultaneously, commonly used in modern CPU instruction sets like SSE and AVX, whereas MIMD architectures manage complex parallelism with multiple instruction streams across distributed or shared memory systems, requiring advanced synchronization and fault tolerance.
FAQs
What is SIMD architecture?
SIMD architecture processes multiple data points simultaneously using a single instruction, enhancing parallelism in tasks such as vector processing and multimedia applications.
What is MIMD architecture?
MIMD (Multiple Instruction, Multiple Data) architecture allows multiple processors to execute different instructions on different data streams simultaneously, enabling parallel processing in multiprocessor systems.
How does SIMD differ from MIMD?
SIMD (Single Instruction, Multiple Data) executes the same instruction simultaneously on multiple data points, while MIMD (Multiple Instruction, Multiple Data) allows multiple processors to execute different instructions on different data independently.
What are the advantages of SIMD?
SIMD improves processing speed by executing multiple data operations simultaneously, enhances performance in multimedia and scientific applications, reduces power consumption by parallelizing tasks, and maximizes CPU utilization efficiency.
What are the advantages of MIMD?
MIMD architecture offers advantages such as high parallelism, scalability for large and complex tasks, flexibility to execute different programs simultaneously, and efficient resource utilization in multiprocessor systems.
Where is SIMD typically used?
SIMD is typically used in multimedia processing, gaming graphics, scientific simulations, and data parallel applications.
Where is MIMD typically used?
MIMD is typically used in parallel computing systems, high-performance computing, and multiprocessor architectures.