Strict consistency ensures immediate data synchronization across all nodes, guaranteeing that every read reflects the latest write, crucial for applications demanding strong data accuracy. Eventual consistency allows temporary data divergence, with updates propagating asynchronously to achieve consistency over time, suitable for distributed systems prioritizing availability and partition tolerance. Explore further to understand how these consistency models impact system design and performance.
Main Difference
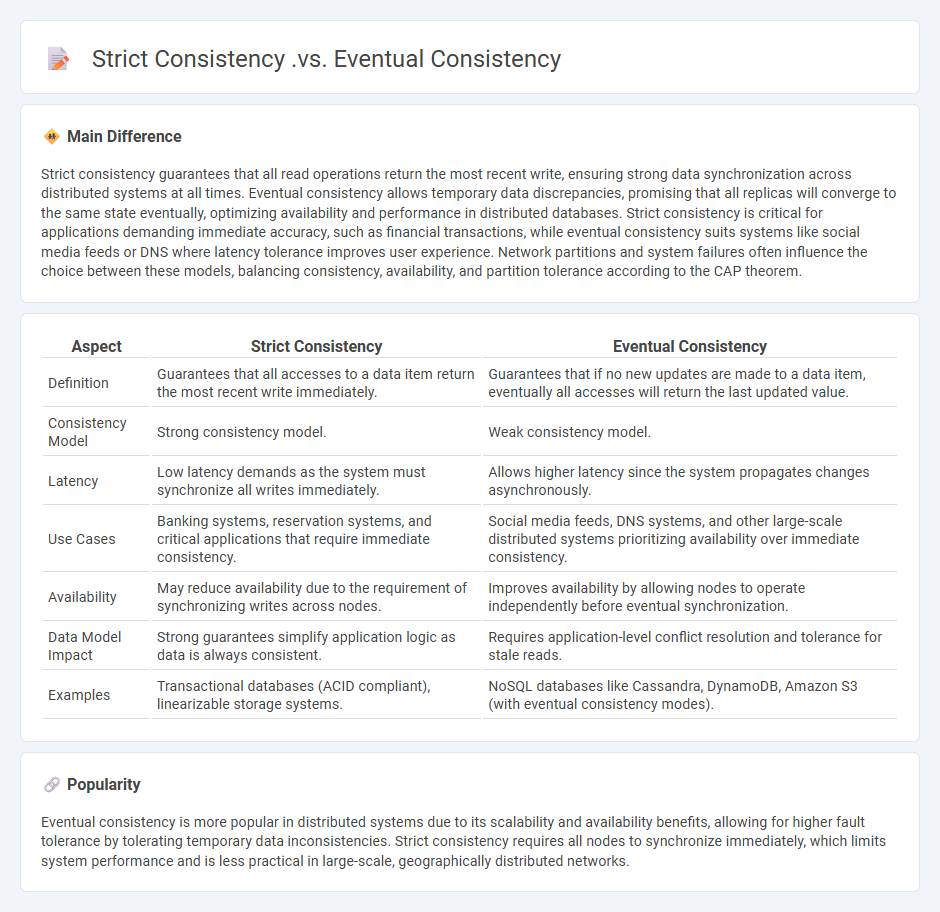
Strict consistency guarantees that all read operations return the most recent write, ensuring strong data synchronization across distributed systems at all times. Eventual consistency allows temporary data discrepancies, promising that all replicas will converge to the same state eventually, optimizing availability and performance in distributed databases. Strict consistency is critical for applications demanding immediate accuracy, such as financial transactions, while eventual consistency suits systems like social media feeds or DNS where latency tolerance improves user experience. Network partitions and system failures often influence the choice between these models, balancing consistency, availability, and partition tolerance according to the CAP theorem.
Connection
Strict consistency requires that all read operations return the most recent write, ensuring immediate uniformity across distributed systems. Eventual consistency allows temporary discrepancies but guarantees that all replicas converge to the same value over time, optimizing availability and partition tolerance. Both concepts address data synchronization but balance consistency, availability, and latency differently within distributed databases and cloud storage architectures.
Comparison Table
| Aspect | Strict Consistency | Eventual Consistency |
|---|---|---|
| Definition | Guarantees that all accesses to a data item return the most recent write immediately. | Guarantees that if no new updates are made to a data item, eventually all accesses will return the last updated value. |
| Consistency Model | Strong consistency model. | Weak consistency model. |
| Latency | Low latency demands as the system must synchronize all writes immediately. | Allows higher latency since the system propagates changes asynchronously. |
| Use Cases | Banking systems, reservation systems, and critical applications that require immediate consistency. | Social media feeds, DNS systems, and other large-scale distributed systems prioritizing availability over immediate consistency. |
| Availability | May reduce availability due to the requirement of synchronizing writes across nodes. | Improves availability by allowing nodes to operate independently before eventual synchronization. |
| Data Model Impact | Strong guarantees simplify application logic as data is always consistent. | Requires application-level conflict resolution and tolerance for stale reads. |
| Examples | Transactional databases (ACID compliant), linearizable storage systems. | NoSQL databases like Cassandra, DynamoDB, Amazon S3 (with eventual consistency modes). |
Data Synchronization
Data synchronization in computer systems ensures consistency and uniformity of data across multiple devices or platforms by continuously updating changes in real-time or scheduled intervals. Technologies such as cloud storage services, database replication, and file synchronization tools enable efficient data synchronization, reducing the risk of discrepancies and data conflicts. Common protocols like SyncML, WebDAV, and rsync facilitate secure and reliable data transfer during synchronization processes. Effective synchronization supports collaborative environments, enhances data integrity, and improves system performance across distributed computing networks.
Real-Time Updates
Real-time updates in computer systems enable instantaneous data processing and immediate reflection of changes across applications and databases. This technology is essential for applications such as financial trading platforms and online gaming, where milliseconds can impact outcomes significantly. Implementing real-time updates requires robust architectures like event-driven models and technologies such as WebSockets, Kafka, or SignalR to ensure low-latency communication. Optimizing these systems enhances user experience by delivering up-to-date information continuously without manual refreshes.
Latency Tolerance
Latency tolerance in computer systems refers to the ability of hardware and software to efficiently manage and mitigate delays in data processing and communication. Techniques such as prefetching, pipelining, and asynchronous processing enhance performance by reducing the impact of latency on overall system throughput. Latency tolerance is critical in high-performance computing, real-time applications, and distributed systems where timely data access is essential. Modern processors incorporate speculative execution and out-of-order processing to further improve latency tolerance and maintain instruction flow.
Conflict Resolution
Conflict resolution in computer systems involves techniques to manage and resolve discrepancies in data, processes, or access rights in multi-user or distributed environments. Algorithms such as version control systems, locking mechanisms, and consensus protocols like Paxos or Raft play crucial roles in ensuring consistency and system reliability. Effective conflict resolution improves data integrity, minimizes downtime, and enhances overall system performance. These methods are essential in databases, cloud computing, and collaborative platforms where concurrent operations frequently occur.
Partition Tolerance
Partition Tolerance in computer systems refers to the ability of a distributed network to continue operating correctly despite the failure of communication links between nodes. This concept is crucial in distributed computing frameworks such as Apache Cassandra and Amazon DynamoDB, which maintain data consistency and availability even when partitions occur. The CAP theorem highlights that systems must compromise between consistency, availability, and partition tolerance, with most modern systems favoring partition tolerance to ensure reliability in unpredictable network environments. Effective partition tolerance mechanisms involve strategies like data replication, consensus algorithms, and failure detection.
Source and External Links
Strong vs Eventual Consistency in System Design - This webpage discusses the differences between strong consistency, which guarantees all reads reflect the most recent write, and eventual consistency, which allows temporary inconsistencies but ensures eventual data convergence.
Eventual vs Strong Consistency in Distributed Databases - This article explains that eventual consistency offers high availability by allowing data inconsistencies temporarily, while strong consistency ensures all nodes have the same data at all times, often at the cost of higher latency.
Eventual Consistency vs. Strong Consistency - This webpage compares the benefits of strong consistency, which ensures consistent data across nodes, with eventual consistency, which prioritizes availability and performance over immediate consistency.
FAQs
What is data consistency in distributed systems?
Data consistency in distributed systems ensures that all nodes or replicas reflect the same valid data state, maintaining accuracy and uniformity across the network despite concurrent updates or failures.
What is strict consistency?
Strict consistency ensures that any read operation returns the most recent write value immediately across all nodes in a distributed system.
What is eventual consistency?
Eventual consistency is a data consistency model in distributed systems where updates to a data item will propagate to all replicas over time, ensuring that all copies eventually become consistent without requiring immediate synchronization.
How do strict and eventual consistency differ?
Strict consistency ensures all reads reflect the most recent write immediately, while eventual consistency allows reads to return stale data temporarily but guarantees all updates will propagate eventually.
What are the benefits of strict consistency?
Strict consistency ensures immediate data accuracy, simplifies application design, prevents stale reads, and guarantees all users see the most recent updates.
What are the advantages of eventual consistency?
Eventual consistency improves system availability, enhances scalability, reduces latency, and supports partition tolerance in distributed databases.
When should you use strict vs eventual consistency?
Use strict consistency when applications require immediate and accurate data accuracy, such as in financial transactions or inventory management; use eventual consistency for high-availability and scalable systems like social media feeds or caching where temporary data divergence is acceptable.