Von Neumann Architecture features a single memory space for both instructions and data, enabling simpler hardware design but causing potential bottlenecks in processing speed known as the von Neumann bottleneck. Harvard Architecture uses separate memory and pathways for instructions and data, allowing simultaneous access that increases overall throughput and efficiency, particularly in digital signal processing and embedded systems. Explore the detailed advantages and applications of these architectures to understand their impact on modern computing systems.
Main Difference
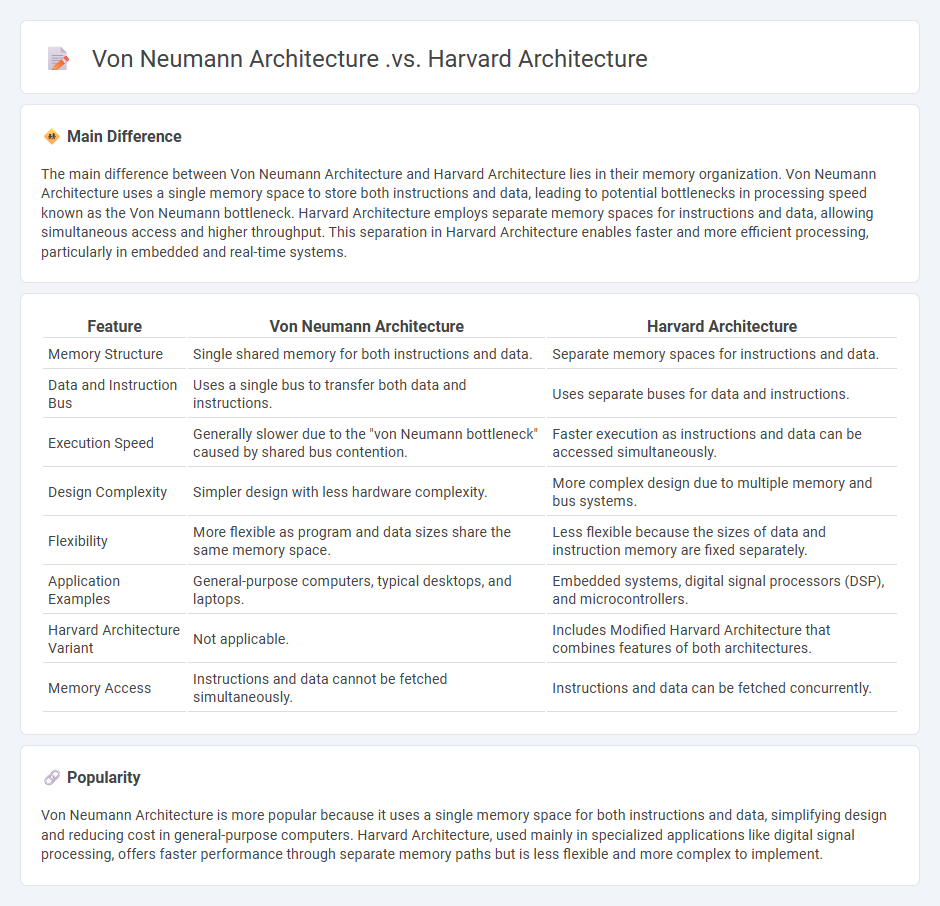
The main difference between Von Neumann Architecture and Harvard Architecture lies in their memory organization. Von Neumann Architecture uses a single memory space to store both instructions and data, leading to potential bottlenecks in processing speed known as the Von Neumann bottleneck. Harvard Architecture employs separate memory spaces for instructions and data, allowing simultaneous access and higher throughput. This separation in Harvard Architecture enables faster and more efficient processing, particularly in embedded and real-time systems.
Connection
Von Neumann Architecture and Harvard Architecture are both foundational computer system designs that define how a processor accesses memory for instructions and data. Von Neumann architecture uses a single shared memory for instructions and data, enabling flexible but sequential processing, while Harvard architecture employs separate memories and buses for instructions and data, allowing simultaneous access and improved speed. Modern processors often blend aspects of both architectures to optimize performance and efficiency.
Comparison Table
| Feature | Von Neumann Architecture | Harvard Architecture |
|---|---|---|
| Memory Structure | Single shared memory for both instructions and data. | Separate memory spaces for instructions and data. |
| Data and Instruction Bus | Uses a single bus to transfer both data and instructions. | Uses separate buses for data and instructions. |
| Execution Speed | Generally slower due to the "von Neumann bottleneck" caused by shared bus contention. | Faster execution as instructions and data can be accessed simultaneously. |
| Design Complexity | Simpler design with less hardware complexity. | More complex design due to multiple memory and bus systems. |
| Flexibility | More flexible as program and data sizes share the same memory space. | Less flexible because the sizes of data and instruction memory are fixed separately. |
| Application Examples | General-purpose computers, typical desktops, and laptops. | Embedded systems, digital signal processors (DSP), and microcontrollers. |
| Harvard Architecture Variant | Not applicable. | Includes Modified Harvard Architecture that combines features of both architectures. |
| Memory Access | Instructions and data cannot be fetched simultaneously. | Instructions and data can be fetched concurrently. |
Shared vs. Separate Memory
Shared memory architecture in computers allows multiple processors to access a common memory space, improving data exchange efficiency and simplifying programming models for parallel processing. Separate memory architecture assigns distinct memory units to each processor, reducing memory contention and enhancing scalability in distributed systems. Modern multiprocessor systems often combine both approaches, utilizing shared memory for tightly-coupled tasks and separate memory for large-scale, distributed applications. High-performance computing relies on optimized memory management techniques to balance latency, bandwidth, and processor coordination effectively.
Data and Instruction Bus
A data and instruction bus in a computer serves as a communication pathway that transfers data and instructions between the central processing unit (CPU), memory, and peripheral devices. The data bus width, typically ranging from 8 to 64 bits, directly influences the system's processing speed and bandwidth. Instruction buses specifically carry executable commands from memory to the CPU, enabling efficient instruction cycle execution. Modern computer architectures integrate unified buses or separate buses to optimize performance and reduce bottlenecks during data transfer.
Speed and Performance
Computer speed and performance are primarily determined by the central processing unit (CPU) clock speed, measured in gigahertz (GHz), which dictates how many cycles per second the processor can execute. Random Access Memory (RAM), especially its size and type like DDR4 or DDR5, significantly influences multitasking efficiency and overall system responsiveness. Storage devices such as solid-state drives (SSD) offer faster data access speeds compared to traditional hard disk drives (HDD), reducing load times for applications and operating systems. Graphics processing units (GPUs) also contribute to performance in tasks involving image rendering, gaming, and video editing by offloading complex calculations from the CPU.
Complexity and Cost
Computer complexity often refers to both computational complexity, which measures the efficiency of algorithms in terms of time and space, and system complexity involving hardware and software integration. High complexity in computer systems typically leads to increased development and maintenance costs, influenced by factors such as processor architecture, memory hierarchy, and software design patterns. Cost analysis in computing includes not only initial investment in hardware and software but also operational expenses like energy consumption and scalability challenges. Efficient complexity management enables optimized performance while minimizing total cost of ownership (TCO) for enterprises and individual users.
Application Suitability
Application suitability in computer systems determines how well software meets specific hardware capabilities and user requirements. Factors such as processing power, memory capacity, operating system compatibility, and network connectivity play crucial roles in ensuring optimal performance. Evaluating application demands against device specifications helps prevent software crashes, improves user experience, and maximizes resource efficiency. In sectors like enterprise IT and gaming, matching applications to computers with adequate GPUs and CPU frequencies above 3.0 GHz significantly enhances functionality and responsiveness.
Source and External Links
Difference between Von Neumann and Harvard Architecture - Von Neumann architecture stores program data and instructions in the same memory, making it simple and cost-effective, while Harvard architecture uses separate memories for data and instructions, enabling simultaneous access and potentially higher performance.
Harvard Architecture versus Von Neumann Architecture - YouTube - Harvard architecture separates program and data memories to avoid the von Neumann bottleneck and allows simultaneous fetching of instructions and data, which is beneficial especially in DSP and embedded systems.
Difference Between Von Neumann and Harvard Architecture - BYJU'S - Von Neumann architecture requires less complexity as it accesses a single common memory for instructions and data, while Harvard architecture requires more complex design due to separate memory units for instructions and data.
FAQs
What is Von Neumann architecture?
Von Neumann architecture is a computer design model featuring a single memory space storing both instructions and data, with a central processing unit (CPU) that sequentially fetches, decodes, and executes instructions.
What is Harvard architecture?
Harvard architecture is a computer architecture with separate memory spaces and buses for instructions and data, enabling simultaneous access and increased processing speed.
What is the main difference between Von Neumann and Harvard architectures?
The main difference between Von Neumann and Harvard architectures is that Von Neumann architecture uses a single memory space for both instructions and data, while Harvard architecture uses separate memory spaces for instructions and data.
How do memory systems differ in Von Neumann and Harvard architectures?
Von Neumann architecture uses a single shared memory system for both instructions and data, whereas Harvard architecture employs separate memory systems for instructions and data, enabling simultaneous access and increased throughput.
Which architecture is faster for data processing and why?
Dataflow architecture is faster for data processing because it allows parallel execution by triggering operations based on data availability rather than sequential instruction execution.
Where is Von Neumann architecture commonly used?
Von Neumann architecture is commonly used in general-purpose computers, including desktops, laptops, and servers.
Where is Harvard architecture typically applied?
Harvard architecture is typically applied in embedded systems, digital signal processors (DSPs), and microcontrollers for improved processing speed through separate memory storage for instructions and data.