Supervised learning in AI engineering involves training algorithms on labeled datasets, enabling models to make predictions based on input-output pairs. Unsupervised learning, by contrast, focuses on identifying patterns and structures in unlabeled data without predefined categories. Explore the key differences and applications of these learning paradigms to optimize your AI solutions.
Main Difference
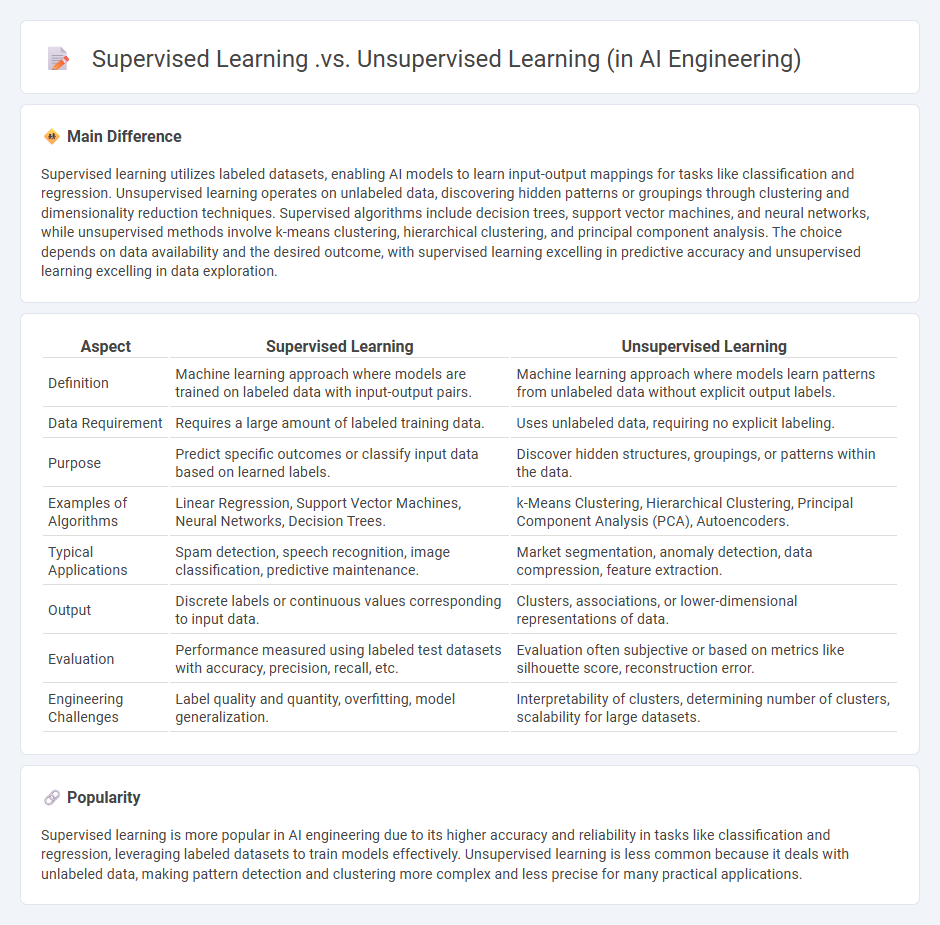
Supervised learning utilizes labeled datasets, enabling AI models to learn input-output mappings for tasks like classification and regression. Unsupervised learning operates on unlabeled data, discovering hidden patterns or groupings through clustering and dimensionality reduction techniques. Supervised algorithms include decision trees, support vector machines, and neural networks, while unsupervised methods involve k-means clustering, hierarchical clustering, and principal component analysis. The choice depends on data availability and the desired outcome, with supervised learning excelling in predictive accuracy and unsupervised learning excelling in data exploration.
Connection
Supervised learning and unsupervised learning are connected through their shared goal of extracting meaningful patterns from data to improve AI model performance. Both methods involve algorithms that process input data, with supervised learning relying on labeled datasets to map inputs to outputs, while unsupervised learning detects hidden structures in unlabeled data. Together, these techniques enable comprehensive data analysis frameworks, enhancing predictive accuracy and discovery in AI engineering applications.
Comparison Table
| Aspect | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Definition | Machine learning approach where models are trained on labeled data with input-output pairs. | Machine learning approach where models learn patterns from unlabeled data without explicit output labels. |
| Data Requirement | Requires a large amount of labeled training data. | Uses unlabeled data, requiring no explicit labeling. |
| Purpose | Predict specific outcomes or classify input data based on learned labels. | Discover hidden structures, groupings, or patterns within the data. |
| Examples of Algorithms | Linear Regression, Support Vector Machines, Neural Networks, Decision Trees. | k-Means Clustering, Hierarchical Clustering, Principal Component Analysis (PCA), Autoencoders. |
| Typical Applications | Spam detection, speech recognition, image classification, predictive maintenance. | Market segmentation, anomaly detection, data compression, feature extraction. |
| Output | Discrete labels or continuous values corresponding to input data. | Clusters, associations, or lower-dimensional representations of data. |
| Evaluation | Performance measured using labeled test datasets with accuracy, precision, recall, etc. | Evaluation often subjective or based on metrics like silhouette score, reconstruction error. |
| Engineering Challenges | Label quality and quantity, overfitting, model generalization. | Interpretability of clusters, determining number of clusters, scalability for large datasets. |
Labeled Data
Labeled data in engineering refers to datasets where each data point is tagged with relevant information, enabling supervised learning algorithms to accurately identify patterns and make predictions. This type of data is crucial for applications such as predictive maintenance, fault detection, and quality control in fields like civil, mechanical, and electrical engineering. High-quality labeled datasets improve model performance by providing clear examples that guide algorithm training and validation. Efficient labeling techniques, including manual annotation and automated labeling tools, are essential for maintaining data accuracy and reliability in engineering projects.
Classification
Classification in engineering involves organizing data, materials, or components into categories based on shared characteristics to improve system design, analysis, and decision-making. It plays a critical role in machine learning models, fault diagnosis, quality control, and resource management across various engineering domains, such as civil, mechanical, electrical, and software engineering. Advanced classification algorithms like support vector machines, random forests, and neural networks enhance predictive accuracy and operational efficiency in engineering applications. Effective classification accelerates problem-solving and innovation by structuring complex technical information into manageable and interpretable formats.
Clustering
Clustering in engineering involves grouping data points or components based on similarity to improve design, analysis, and problem-solving efficiency. Techniques such as k-means, hierarchical clustering, and DBSCAN are widely applied in fields like structural health monitoring, manufacturing process optimization, and materials science. These methods enable engineers to identify patterns, detect anomalies, and enhance predictive maintenance strategies by processing large datasets accurately. Engineering clustering drives innovation by transforming raw data into actionable insights for system optimization and quality control.
Feature Extraction
Feature extraction in engineering involves transforming raw data into meaningful representations to enhance machine learning model performance. Techniques such as principal component analysis (PCA), wavelet transform, and Fourier transform are frequently used to reduce dimensionality and highlight relevant patterns in sensor data or images. Effective feature extraction improves predictive accuracy in applications like fault detection, control systems, and signal processing. Engineering disciplines including mechanical, electrical, and civil leverage feature extraction to optimize diagnostics and enhance system monitoring.
Model Generalization
Model generalization in engineering refers to the ability of a computational or mathematical model to accurately predict outcomes across varied datasets and real-world scenarios beyond the initial training environment. Robust generalization minimizes overfitting, ensuring the model's applicability in domains such as structural analysis, system optimization, and predictive maintenance. Techniques like cross-validation, regularization, and the use of diverse training data enhance generalization capabilities. Successful model generalization drives innovation in engineering fields like aerospace, civil, and mechanical engineering, improving design efficiency and reliability.
Source and External Links
Supervised vs Unsupervised Learning Explained - Seldon - Supervised learning uses labeled input-output data to predict outcomes or classify new data, while unsupervised learning uses unlabeled data to discover patterns or cluster data without predefined labels.
Difference between Supervised and Unsupervised Learning - GeeksforGeeks - Supervised learning excels in predictive tasks with known outputs using labeled datasets, whereas unsupervised learning focuses on finding hidden relationships or trends in raw, unlabeled data such as clustering or anomaly detection.
Supervised vs. unsupervised learning - Google Cloud - The key difference is data labeling: supervised learning uses labeled data with known correct outputs for training models to minimize error in predictions, whereas unsupervised learning finds inherent patterns in unlabeled data without specific guidance.
FAQs
What is supervised learning in AI?
Supervised learning in AI is a machine learning approach where algorithms learn from labeled training data to predict outcomes or classify new inputs accurately.
What is unsupervised learning in AI?
Unsupervised learning in AI is a machine learning technique where algorithms analyze and identify patterns or structures in unlabeled data without predefined output labels, enabling clustering, dimensionality reduction, and anomaly detection.
How does supervised learning differ from unsupervised learning?
Supervised learning uses labeled data to train models for prediction, while unsupervised learning explores patterns in unlabeled data without predefined outputs.
What are common algorithms for supervised learning?
Common algorithms for supervised learning include linear regression, logistic regression, decision trees, support vector machines (SVM), k-nearest neighbors (KNN), random forests, gradient boosting machines (GBM), and neural networks.
What are common techniques used in unsupervised learning?
Common techniques used in unsupervised learning include clustering algorithms (K-means, hierarchical clustering, DBSCAN), dimensionality reduction methods (PCA, t-SNE, Autoencoders), anomaly detection, and association rule learning (Apriori, Eclat).
When should supervised or unsupervised learning be used?
Use supervised learning when labeled data is available to train models on input-output mappings; use unsupervised learning when only unlabeled data exists, aiming to discover hidden patterns or groupings.
What are the main challenges of supervised and unsupervised learning?
Supervised learning faces challenges like requiring large labeled datasets, overfitting, and difficulty generalizing to unseen data; unsupervised learning struggles with defining meaningful features, evaluating model performance, and handling high-dimensional or noisy data.